
在这个入门中我们将走一遍GemFire应用程序代码,学习GemFire Enterprise基本的特性。这个应用详解了GemFire怎么在VMs宕机情况下并不中断服务。当应用运行时动态地添加更多的存储,并且提供更小的延迟来访问你的数据。
入门概览
主要的概念
本入门涵盖了以下概念:
GemFire Distributed
System
运行在GemFire上的VMs组成了分布式系统。每一个MV都作为一个GemFire对等体存在。启动GemFire对等体,在每个VM对等体上你创建了一个缓存。每一个缓存管理到其他VM对等体的连接。通过UDP多播或者TCP位置服务,互相发现。
Regions
Region是一个分布式系统之上的抽象概念。一个Region允许你在系统的多个VM中存储数据,不用考虑数据存在那个对等体上。Region给你一个map接口能透明地从合适的VM上获取数据。这个Region类扩展了java.util.Map接口,
但是他也支持查询和事务。
Replicated regions
一个Replicated region保存着所有分区的数据拷贝
Partitioned regions
Partitioned regions只保存一部分分区的数据拷贝
Client caching
GemFire分布式系统是一个网格结构,所有的Peer直接互相连接。GemFire也支持客户端,客户端有他们自己的本地数据缓存,他们能够更新他们的本地缓存,通过注册服务器来更新改变的数据。
Shared-nothing persistence
GemFire支持’非共享’持久化,每一个peer持久化数据到本地磁盘,GemFire持久化也允许你在磁盘上维护一份配置的数据拷贝。
分布式系统和Region
1. 开始一个locator
通过UDP多播或者TCP位置服务GemFire能够动态发现成员,其中运行TCP位置服务的被称为Locator,Locator作为单独的进程运行,每一个新的VM连接到已有的Peer上。在这个例子中我们将要使用Locator。
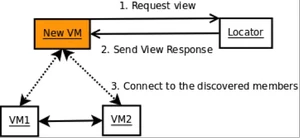
2. 创建一份缓存
你将要在GemFire对等体上存储一些数据。第一步启动GemFire对等体创建一份缓存。缓存是GemFire的中心模块。他管理着到其他GemFire对等体的连接。
— ”locators” 属性告诉缓存哪一个locator用来发现其他的GemFire VM。
—“mcast-port” 属性告诉GemFire是否用多播发现来找到对等体。
—“log-level” 属性控制GemFire内部日志级别。设定error是为了限制消息的数量,这个将在”console”中显示。在调用创建结束后,对等体已经发现了其他的对等体同时连接他们。
3. 启动对等体
运行IDE中运行两次peer.java ,对等体启动,互相连接。
4. 创建People region(a replicated region)
GemFire Region是一个键值集合。他扩展了java.util.concurrent.ConcurrentMap接口。Region最简单的类型就是replicated region。每一个拥有replicated region的peer都存储一份整个region的拷贝。对replicated region所做的任何改变都同步发送到所有的peer中。
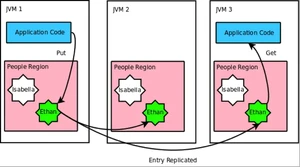
a. 查看一下GemFireDAO中initPeer方法,用RegionFactory创建region,在这个例子中,people region用RegionShortcut.REPLICATE构造,告诉工厂使用replicated region的配置,这个方法添加了缓存监听器到region。当region中的数据改变,你能够利用缓存监听器接受改变通告。这个应用包含了LoggingCacheListener类,他能把改变打印到控制台,能够让你看到条目怎么被分布的。
b. 看一下addPerson方法。通过调用region.put()方法添加条目到region。
public void addPerson(String name, Profile profile) {
people.put(name, profile);
}
通过分布people对象到所有的对等体当中。在完成调用之后,每一份对等体都有一份person拷贝。
c. 添加people。在控制台中键入
你将在窗口中看到
5.创建Posts region(partitioned region)
你创建了大量的posts。如果你不想在每一台服务器上都拥有一份拷贝。
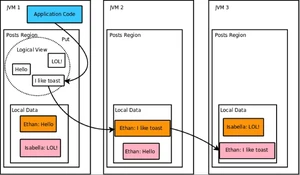
看一下GemFireDAO的initPeer方法,你能使用PARTITION_XXX快捷键创建分区。创建posts区,这个方法使用PARTITIONED_REDUNDANT快捷键告诉GemFire创建一个分区来维护主备
拷贝。
5. 启动对等体应用
再启动一个对等体
6. 添加一个帖子
你将要看到只有一个VM上的监听器被调用。这是因为分区选择其中一份拷贝到主拷贝中。缺省情况下,GemFire只调用了维护主拷贝的对等体的监听器。
7. 用posts命令列出可用的posts命令
GemFire会从每一个各自的对等体中获取他们,
如果你杀了一个VMs,你仍然能够列出所有的条目。这就是VM的备份能力。
8. kill掉peers
Client/server 缓存
你有一个全工作系统,但是现在UI代码正运行在相同的VM上,这些用例工作地很好,
但是对于其他人不需要,比如,如果你在UI层有一个web server,你可能想到增加或者减少web server的数量而不改变data server。或者你只需要100G的服务器,但是可能有数万个客户端会访问它。对于这个例子,有一个专门的GemFire服务器来服务GemFire客户端会更有意义。
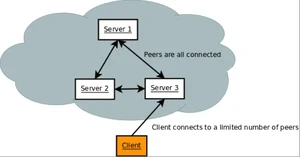
GemFire服务器是GemFire对等体,但是他们也能监听客户端连接的端口,而GemFire客户端连接一个限制数量的服务器。
对于传统的peers,GemFire服务器仍然需要定义region。你可能已经有了peer代码,又创建了一个CacheServer,但是这个例子使用了cacheserver脚本。Cacheserver脚本从cache xml文件中读取了cache配置。Cache.xml 以声明的方式在缓存中定义region。
1. 用xml配置GemFire
所有在java代码能做的也都能在xml中定义,
<cache>
<region name="people" refid="REPLICATE">
<region-attributes>
<cache-listener>
<class-name>com.gemstone.gemfire.tutorial.storage.LoggingCacheListener</class-name>
</cache-listener>
</region-attributes>
</region>
<region name="posts" refid="PARTITION_REDUNDANT">
<region-attributes>
<cache-listener>
<class-name>com.gemstone.gemfire.tutorial.storage.LoggingCacheListener</class-name>
</cache-listener>
</region-attributes>
</region>
</cache>
1. 启动缓存服务器
Cacheserver 脚本启动了jaguar对等体(监听客户端连接),又启动了两个缓存服务器,
3. 启动一个客户端
启动一个客户端和启动GemFire peer是一样的。在Jaguar客户端上,你创造一个ClientCache
连接到Locator来发现服务器,看一下GemFire DAO.initClient方法。这个方法所做的就是创建ClientCache。
一旦你创建一个ClientCache,他便维护了一个类似于JDBC的连接池。然而你不需要用GemFire从池中来做查询连接和返回他们,这个是自动发生的。池定位属性告诉你客户端怎么发现服务器。客户端使用相同的Locator发现缓存服务器。
设定订阅功能开启,订阅冗余属性运行客户端订阅更新服务端条目。如果你订阅通告(任何人添加的),这个更新被异步发送到客户端。因为更新被异步发送,他们需要在服务端队列化。提交冗余设定控制多少队列拷贝在服务端维护。
设定冗余级别为1意味着你能宕掉1个服务器而没有任何的消息丢失。
4. 创建一个proxy region,在客户端发Post消息
在客户端创建一个region类似于在peer中创建region。有两个类型的client region,proxy region和caching region。Proxy region并不在客户端存数据。CACHING_PROXY region允许客户端存储键值。这个例子使用了大量的posts,这样你不用在客户端缓存任何的posts。你能创建一个带有PROXY 的proxy region。看一看GemFireDAO.initPeer方法。这个方法创建了posts region
posts = cache.<PostID, String>createClientRegionFactory(PROXY)
.create("posts");
5.在客户端创建一个cache proxy region,People
你并没有很多people,所以在这个例子当中客户端缓存所有的people。第一你创建了一个有本地存储的region,ClientRegionShortcut.CACHING_PROXY。在initClient方法中,people region被创建。
6.调用registerInterest方法订阅从服务器上来的通告。
通过创建一个CACHING_PROXY,你能告诉GemFire缓存任何的people你从客户端创建出来的。然而,你也能选择任何的更新到people region的从其他的peer 或者别的客户端通过调用registerInterest方法。在这个案例中,你在所有people中想要register interest,这样你缓存整个people region在客户端。正则表达式匹配了所有的键值在people region中的。看一下initClient方法调用registerInterestRegex,
people.registerInterestRegex(".*");
当registerInterestRegex方法被调用时,客户端下载已经存在的people。当一个new person 被添加到server上时,他被推到客户端。
7.从client中迭代键值
public Set<String> getPeople() {
return people.keySet();
}
public Set<PostID> getPosts() {
if(isClient) {
return posts.keySetOnServer();
} else {
return posts.keySet();
}
}
8.在IDE中运行客户端应用程序
添加和停止Cache Servers
你能够动态的添加peers到服务器中当系统正在运行时。New peers动态地被其他peer和客户端发现。New peer自动接受一份拷贝由replicated region创建的。然而, partitioned region并不自动地分布数据到new peer如果你不显式地命令GemFire负载均衡partitioned region。
在cacheserver脚本中, 你能通过一个命令行来指定一个new peer将要触发一个所有partitioned region的负载均衡。
停止cache servers
1. 停止其中之一的cacheservers
数据仍然可用, 客户端自动忽略死掉的服务器。
2.在移动到下一步之前, 停止其他的缓存服务器。你能保持客户端处于运行状态。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/10468.html