

之前分享了很多 、 的 Python 爬虫文章,本文将从原理到实战带领大家入门另一个强大的框架 。如果对感兴趣的话,不妨跟随本文动手做一遍!
是:由语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据,只需要实现少量的代码,就能够快速的抓取。
Scrapy框架的运行原理看下面一张图就够了(事实上原理是比较复杂的,也不是三言两语能够说清楚的,因此感兴趣的读者可以进一步阅读更多的相关文章来了解,本文不做过多讲解)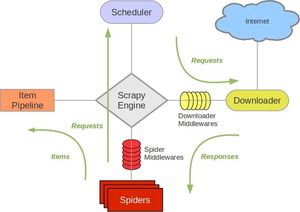
Scrapy主要包括了以下组件:
- 引擎(Scrapy Engine)
- Item 项目
- 调度器(Scheduler)
- 下载器(Downloader)
- 爬虫(Spiders)
- 项目管道(Pipeline)
- 下载器中间件(Downloader Middlewares)
- 爬虫中间件(Spider Middlewares)
- 调度中间件(Scheduler Middewares)
3.1安装
第一种:在命令行模式下使用pip命令即可安装:
第二种:首先下载,然后再安装:
进入下载目录后执行下面命令安装:
3.2使用
使用大概分为下面四步1 创建一个scrapy项目
2 生成一个爬虫
3 提取数据
4 保存数据
3.3 程序运行
在命令中运行爬虫
在pycharm中运行爬虫
爬虫框架的具体使用步骤如下:
“”
- 选择目标网站
- 定义要抓取的数据(通过Scrapy Items来完成的)
- 编写提取数据的spider
- 执行spider,获取数据
- 数据存储
当我们创建了一个scrapy项目后,继续创建了一个spider,目录结构是这样的:
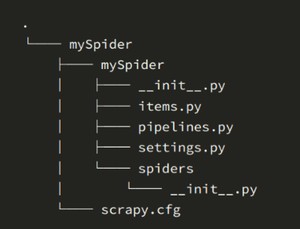
下面来简单介绍一下各个主要文件的作用:
“scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
”
5.1 scrapy.cfg文件
项目配置文件。这个是文件的内容:
5.2 mySpider/
项目的Python模块,将会从这里引用代码
5.3 mySpider/items.py
项目的目标文件
定义scrapy items的模块,示例: name = scrapy.Field()
5.4 mySpider/pipelines.py
项目的管道文件
这个文件也就是我们说的管道,当Item在Spider中被收集之后,它将会被传递到Item Pipeline(管道),这些Item Pipeline组件按定义的顺序处理Item。每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
5.5 mySpider/settings.py
项目的设置文件
省略号省略代码,一般重要点,给了注释
6.mySpider/spiders/ :存储爬虫代码目录
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据,但是一般使用的不多。感兴趣的查看官方文档:
官方文档
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及 。
- 当shell载入后,将得到一个包含response数据的本地 response 变量,输入 将输出response的包体,输出 可以看到response的包头。
- 输入 时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用 或 来对 response 进行查询。
- Scrapy也提供了一些快捷方式, 例如 或同样可以生效(如之前的案例)。
Selectors选择器
“Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
”
Selector有四个基本的方法,最常用的还是xpath:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
- extract(): 序列化该节点为字符串并返回list
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
- re(): 根据传入的正则表达式对数据进行提取,返回字符串list列表
本节,我将使用Scrapy爬取站酷数据作为示例

7.1 案例说明
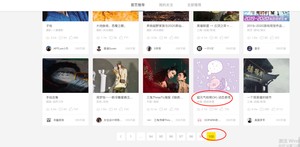
既然已经初步了解了scrapy的工作流程以及原理,我们来做一个入门的小案例,爬取站酷首页推荐的item信息。如下图所示,一个小方框就是一个item信息。我们要提取每一个item的六个组成部分:
- imgLink(封面图片链接);
- title(标题);
- types(类型);
- vistor(人气);
- comment(评论数);
- likes(推荐人数)
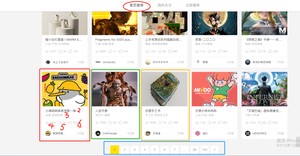
然后只是一个页面的item,我们还要通过翻页实现批量数据采集。
7.2 文件配置
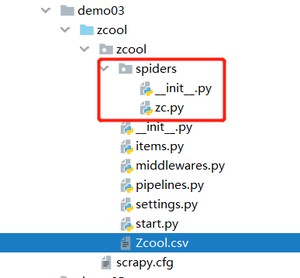
目录结构
在上一篇中我们说明了新建scrapy项目(zcool)和spider项目(zc),这里不再赘述,然后得到我们的目录结构如下图所示:
start.py文件
然后为了方便运行,在zcool目录下新建start文件。并进行初始化设置。
settings.py文件
在这个文件里我们需要做几样设置????
避免在程序运行的时候打印log日志信息
添加请求头:

打开管道:
item.py文件
7.3 页面数据提取
首先我们在站酷页面使用xpath-helper测试一下:
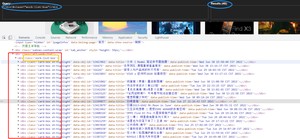
然后zc.py文件里面初步测试一下:
运行结果如下图所示:
没有问题,然后我们对各种信息分别解析提取,
解释: xpath提取数据方法:
注意:
“get() 、getall() 方法是新的方法,extract() 、extract_first()方法是旧的方法。extract() 、extract_first()方法取不到就返回None。get() 、getall() 方法取不到就raise一个错误。
”
item实例创建(yield上面一行代码)
这里我们之前在目录文件配置的item文件中已经进行了设置,对于数据存储,我们在爬虫文件中开头要导入这个类:
然后使用yield返回数据。
为什么使用yield而不是return
不能使用return这个无容置疑,因为要翻页,使用return直接退出函数;而对于yield:在调用for的时候,函数内部不会立即执行,只是返回了一个生成器对象。在迭代的时候函数会开始执行,当在yield的时候,会返回当前值(i)。之后的这个函数会在循环中进行,直到没有下一个值。
7.4 翻页实现批量数据采集
通过上面的代码已经可以初步实现数据采集,只不过只有第一页的,如下图所示:
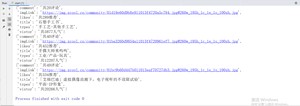
但是我们的目标是100个页面的批量数据采集,所以代码还需要修改。针对翻页这里介绍两种方式:
方式一:我们首先在页面中定位到下一页的按钮,如下图所示:
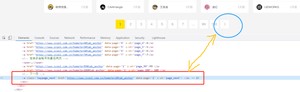
然后编写如下代码,在for循环完毕后。
scrapy.Request(): 把下一页的url传递给Request函数,进行翻页循环数据采集。
注意方式一只有下一页按钮它的href对应属性值和下一页的url一致才行。
方式二:定义一个全局变量count = 0,每爬取一页数据,令其加一,构建新的url,再使用scrapy.Request() 发起请求。
如下图所示:
这两种方式在实际案例中择机采用。
7.5 数据存储
数据存储是在pipline.py中进行的,代码如下:
解释:
- line1: 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
- line2: 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
- line3: 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
- line4: 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
- line5: 写入spider传过来的具体数值,注意在spider文件中yield的item,是一个由类创建的实例对象,我们写入数据时,写入的是 字典,所以这里还要转化一下。
- line6: 写入完返回
7.6 程序运行
因为之前创建了start.py文件,并且对它就行了初始化设置,现在运行爬虫程序不需要在控制台中输入命令:
直运行start.py文件:得到如下结果:
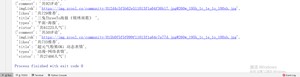
对应于页面:
打开csv文件如下图所示:(由于csv文件在word中乱码了,此处我是用Notepad++打开)

没有问题,数据采集完毕。
7.7. 总结
入门案例,需要细心,主要是基础知识的巩固,以便于为进阶学习做好准备。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/15040.html