
超详细讲解哈夫曼树(Huffman Tree)以及哈夫曼编码的构造原理、方法,并用代码实现。
路径:从树中一个结点到另一个结点之间的分支构成这两个结点间的路径。
结点的路径长度:两结点间路径上的分支数。

树的路径长度:从树根到每一个结点的路径长度之和。记作: TL 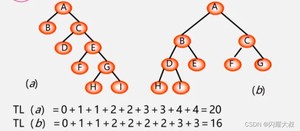
权(weight)又称权重:将树中结点赋给一个有着某种含义的数值,(具体的意义根据树使用的场合确定)则这个数值称为该结点的权。比如之前提到的判断树中5%表示对应分数段人在总人数中的比例
结点的带权路径长度:从根结点到该结点之间的路径长度与结点上权的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和。
树的路径长度:从树根到每一个结点的路径长度之和。
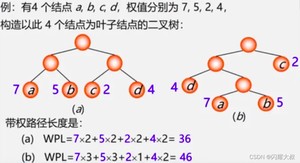
哈夫曼树:最优树,带权路径长度(WPL)最短的树
“带权路径长度最短”是在“度相同”的树中比较而得的结果,因此有最优二叉树、最优三叉树之称。
哈夫曼树:最优二叉树,带权路径长度(WPL)最短的二叉树,因为构造这种树的算法是由哈夫曼教授于1952年提出的,所以被称为哈夫曼树,相应的算法称为哈夫曼算法。
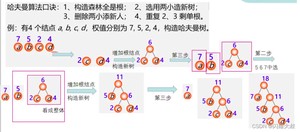
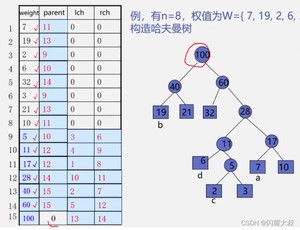
哈夫曼算法(构造哈夫曼树的方法)
(1)根据n个给定的权值(W1,W2,..., Wn)构成n棵二叉树的森林F=(T1, T2,.., Tn),其中Ti只有一个带权为Wi;的根结点。
构造森林全是根
(2)在F中选取两棵根结点的权值最小的树作为左右子树,构造一棵新的二叉树,且设置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
选用两小造新树
(3)在F中删除这两棵树,同时将新得到的二叉树加入森林中。
删除两小添新人
(4)重复(2)和(3),直到森林中只有一棵树为止,这棵树即为哈夫曼树。
重复2、3剩单根
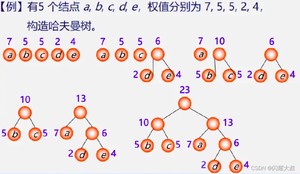
总结
1、在哈夫曼算法中,初始时有n棵二叉树,要经过n-1次合并最终形成哈夫曼树。
2、经过n-1次合并产生n-1个新结点,且这n-1个新结点都是具有两个孩子的分支结点。
可见:哈夫曼树中共有n+n-1 =2n-1个结点,且其所有的分支结点的度均不为1。
构建哈夫曼树时,首先需要确定树中结点的构成。
由于哈夫曼树的构建是从叶子结点开始,不断地构建新的父结点,直至树根,所以结点中应包含指向父结点的指针。但是在使用哈夫曼树时是从树根开始,根据需求遍历树中的结点,因此每个结点需要有指向其左孩子和右孩子的指针。
构建哈夫曼树时,需要每次根据各个结点的权重值,筛选出其中值最小的两个结点,然后构建二叉树。
查找权重值最小的两个结点的思想是:从树组起始位置开始,首先找到两个无父结点的结点(说明还未使用其构建成树),然后和后续无父结点的结点依次做比较,有两种情况需要考虑:
- 如果比两个结点中较小的那个还小,就保留这个结点,删除原来较大的结点;
- 如果介于两个结点权重值之间,替换原来较大的结点;
在远程通讯中,要将待传字符转换成由二进制的字符串
若将编码设计为长度不等的二进制编码,即让待传字符串中出现次数较多的字符采用尽可能短的编码,则转换的二进制字符串便可能减少。
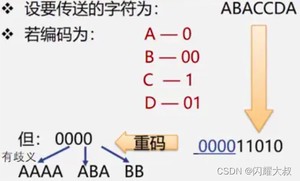
关键:要设计长度不等的编码,则必须使任一字符的编码都不是另一个字符的编码的前缀,这种编码称做前缀编码。
问题:什么样的前缀码能使得电文总长最短?
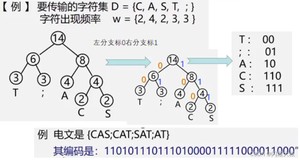
哈夫曼编码方法:
1、统计字符集中每个字符在电文中出现的平均概率(概率越大,要求编码越短)
2、利用哈夫曼树的特点:权越大的叶子离根越近;将每个字符的概率值作为权值,构造哈夫曼树。则概率越大的结点,路径越短。
3、在哈夫曼树的每个分支上标上0或1:
结点的左分支标0,右分支标1
把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码。
两个问题:
1.为什么哈夫曼编码能够保证是前缀编码?
因为没有一片树叶是另一片树叶的祖先,所以每个叶结点的编码就不可能是其它叶结点编码的前缀。(字符都是叶子结点,根到一个字符不会路过另一个字符T)
2.为什么哈夫曼编码能够保证字符编码总长最短?
因为哈夫曼树的带权路径长度最短,故字符编码的总长最短。
性质1哈夫曼编码是前缀码
性质2哈夫曼编码是最优前缀码
使用程序求哈夫曼编码有两种方法:
- 从叶子结点一直找到根结点,逆向记录途中经过的标记。例如,图 3 中字符 c 的哈夫曼编码从结点 c 开始一直找到根结点,结果为:0 1 1 ,所以字符 c 的哈夫曼编码为:1 1 0(逆序输出)。
- 从根结点出发,一直到叶子结点,记录途中经过的标记。例如,求图 3 中字符 c 的哈夫曼编码,就从根结点开始,依次为:1 1 0。
采用方法 1 的实现代码为:
采用第二种算法的实现代码为:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/15220.html