
和是集合框架中的两个常用类,它们都用于存储和管理数据,但在使用方式、功能和性能上有很大的区别。
区别一:用途不同
:是一个基于哈希表的集合,用于存储不重复的元素,它不存储键值对。它实际上是基于 实现的,只存储了键,而值都设置为同一个特殊值(通常是)。
:也是一个基于哈希表的集合,用于存储键值对。它允许你根据键来查找值,因此在存储和检索键值对方面更加灵活。
区别二:数据结构不同
:内部使用哈希表(或哈希集合)来存储元素。哈希表是一个无序的数据结构,元素之间没有特定的顺序。
:内部也使用哈希表,但它存储键值对,其中键和值之间有关联关系。具有键的集合和值的集合,键是唯一的,值可以重复。
区别三:元素类型不同
:存储的是单一的元素类型,如整数、字符串等。它用于存储不重复的对象,通过元素的哈希码来判断重复性。
:存储键值对,键和值可以是不同类型的对象。键用于检索值,每个键都必须是唯一的,值可以重复。
区别四:方法不同
:提供了添加、删除、查找元素的方法,例如, , 等。它没有提供根据键查找值的方法。
:提供了添加键值对、删除键值对、根据键查找值的方法,例如, , 等。它可以根据键来查找对应的值。
的优缺点
优点:
- 唯一性:确保存储的元素不重复,适合用于去重。
- 快速查找:提供了快速的元素查找,因为它使用哈希表。
- 无序性:不保证元素的存储顺序,适合不需要顺序的场景。
缺点:
- 不支持键值对:只存储单一的元素类型,不支持键值对的存储。
- 无法存储关联数据:无法将额外的数据与元素关联,只能存储元素本身。
的优缺点
优点:
- 键值对存储:可以存储键值对,允许将关联数据存储在一起。
- 快速查找:提供了快速的键查找值的能力,适合需要根据键查找值的场景。
- 灵活性:提供了更多的功能,如替换值、遍历键值对等。
缺点:
- 复杂性:相对于,的使用可能更加复杂,因为它需要处理键值对的关系。
- 额外的内存消耗:存储键值对,因此需要额外的内存空间。
的适用场景
- 数据去重:当你需要存储一组数据,但不关心顺序和关联信息,只关心数据是否重复时,使用是合适的。例如,存储一组唯一的用户名或标签。
- 集合运算:适合用于集合运算,如求交集、并集、差集等。
的适用场景
- 键值存储:当你需要将数据与关联的键一起存储时,使用是合适的。例如,存储学生的成绩,其中学生名是键,成绩是值。
- 数据索引:适合用于构建索引,提供快速的查找能力。例如,建立一个电话簿,根据姓名查找电话号码。
- 需要键值对的功能:如果你需要存储关联数据,并且需要使用键来查找值、替换值或遍历键值对,那么是最好的选择。
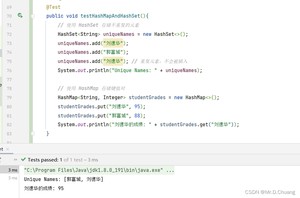
以下是使用和的示例代码:
运行结果:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/16062.html