
Elasticsearch创建索引流程一文中,介绍了ES创建索引的流程。再流程中是调用Lucene的接口来创建索引的。本篇文章主要介绍ES中的索引——倒排索引
倒排索引是搜索引擎非常重要的一种数据结构,什么是倒排索引,倒排索引的原理是什么?
1 索引过程
在讲解倒排索引前,我们先了解索引创建,下图是 Elasticsearch 中数据索引过程的流程。

从上图可以看到,文档未在 ES 中进行索引,而是 由 Analyzer 组件对其执行一些操作并将其拆分为 token/term。然后将这些术语作为倒排索引存储在磁盘中。假设我们有两个名为 name 和 age 字段,当要将文档索引到 ES 时,Analyzers 组件 以某些定界符(有默认定界符,例如空格,句号等)将它们分割开获取 token,再对每个 token 应用特定的过滤器。经过分析的这些标记称为 term。然后将这些 term 针对该字段)存储在倒排列表中。
2 倒排索引
2.1 正排与倒排索引
一般在我们阅读图书,我们会根据目录快速定位想要阅读的章节,过了一段时间,你想要的回顾之前某一个知识点,你发现从目录难以查找到对应的地方,这时你可能就会从索引页从去查找对应内容索引,从而找到页码。
搜索引擎其实跟我们的使用图书很相似,下面我来对图书和搜索引擎进行一个简单的类比,来看一下搜素引擎中正排和倒排索引。
- 图书
- 正排索引-目录页
- 倒排索引-索引页
- 搜索引擎
- 正排索引-文档 Id 到文档内容和单词的关联
- 倒排索引-单词到文档 Id 的关系
2.2 倒排索引的核心组成
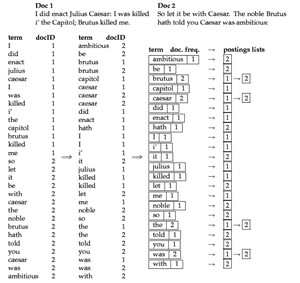
举个例子,假设我们有 3 个文档:
经过分析,文件中的术语如下
倒排列表的元数据结构:
其中:
- DocID:出现某单词的文档ID
- TF(词频):单词在该文档中出现的次数
- POS:单词在文档中的位置
则它们生成的倒排索引
- ES 倒排索引包含两个部分
- 单词词典 (Term Dictionary),索引最小单位,记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般都会非常多,通过 B+ 树或 Hash 表方式以满足高性能的插入与查询
- 倒排列表(Posting List)-由倒排索引项(Posting)组成
- 文档 ID
- 词频 TF,该单词在文档中出现的次数,用于相关性评分
- 位置(Position),单词在文档中分词的位置。用于语句搜索(phrase query)
- 偏移(Offset),记录单词的开始结束位置,实现高亮显示
- 单词词典 (Term Dictionary),索引最小单位,记录所有文档的单词,记录单词到倒排列表的关联关系
在创建索引之前,会对文档中的字符串进行分词。ES中字符串有两种类型,keyword和text。
- keyword类型的字符串不会被分词,搜索时全匹配查询
- text类型的字符串会被分词,搜索时是包含查询
不同的分词器对相同字符串分词的结果大有不同,选择不同的分词器对索引的创建有很大的影响
如拆分“中华人民共和国国歌”
- ik_max_word分词器: 最细粒度拆分,分词结果如下:
- 中华人民共和国
- 中华人民
- 中华
- 华人
- 人民共和国
- 人民
- 人
- 民
- 共和国
- 共和
- 和
- 国国
- 国歌
- ik_smart分词器: 最粗粒度的拆分,分词结果如下:
- 中华人民共和国
- 国歌
可见,再ES中创建索引,选择合适的分词器是很重要的。
该矩阵是表达单词和文档两者之间包含关系的概念模型。
从横向看,每行代表文档包含了哪些单词,比如文档1包含了单词1和单词3,而不包含其它单词。
从纵向看,每列代表了某个单词存在于哪些文档。比如单词1在文档1和文档4中出现过。
简单来说,索引就是实现“单词-文档矩阵”的具体数据结构,而倒排索引则是实现了这种数据结构的具体方式。
倒排索引由两部分构成:
- 单词词典
- 倒排列表
它的结构如下:
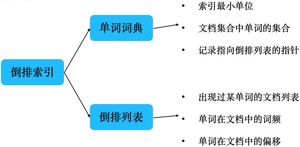
单词词典
单词词典的特性:
- 是文档集合中所有单词的集合
- 它是保存索引的最小单位
- 其中记录着指向倒排列表的指针
单词词典的实现:
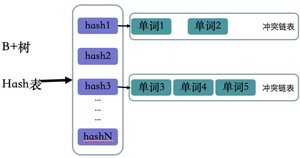
单词词典有两种数据结构实现:B+树和Hash表
B+树和Mysql索引结构中主键索引数据结构一样,这里就不再介绍了
哈希表的key是单词的hash值,值是单词的链表,因为hash算法会有冲突的情况发生,所以这里的值是一个集合,里面保存着相同hash值得单词以及改词指向倒排列表的指针
倒排列表
倒排列表特性:
- 记录出现过某个单词的文档列表
- 同时还记录单词在所有文档中的出现次数和偏移位置
倒排列表元素数据结构:
其中:
- DocID:出现某单词的文档ID
- TF(Term Frequency):单词在该文档中出现的次数
- POS:单词在文档中的位置
举例
有下面单个文档
则他们生成的倒排索引
比如单词“年度”,单词ID为2,在三个文档中出现过,所以逆向文档频率为3,同时倒排索引中的元素也有三个:。拿第一个元素进行说明,他表示“年度”再文档ID为1的文档中出现过1次,出现的位置是第二个单词
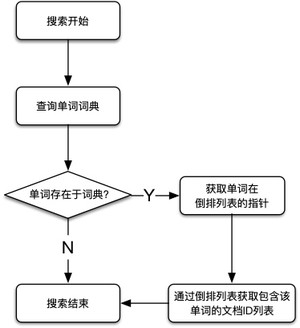
倒排索引的搜索过程
直到了倒排索引的内部结构之后,就能很好理解倒排索引的搜索过程了,其内部搜索过程如下图所示:
- 搜索引擎ElasticSearch源码编译和Debug环境搭建
- 搜索引擎ElasticSearch的启动过程
- Elasticsearch创建索引流程
- Elasticsearch搜索过程详解
- Elasticsearch搜索相关性排序算法详解
- Elasticsearch中的倒排索引
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/2933.html