
学习笔记,主要参考:
- https://zhuanlan.zhihu.com/p/
- https://www.youtube.com/watch?v=ifCDXFdeaaM(hong-yi Lee Diffusion Model原理剖析)
- https://www.bilibili.com/video/BV1Zh411A72y/?spm_id_from=333.999.0.0&vd_source=f16d47823aea3a6e77eecddc27
- https://www.zhihu.com/question//answer/
- https://zhuanlan.zhihu.com/p/
- https://zhuanlan.zhihu.com/p/
- https://zhuanlan.zhihu.com/p/
学习一个网络,使得该网络生成的图像集的分布和真实的图像集的分布越接近越好(生成图像集的分布和真实图像集的分布的KL散度越小越好)。从最大似然估计角度理解,希望生成的图像数据集的分布中产生真实图像数据集中的样本的概率越大越好。
如下图所示,从一个分布z中采样一个vector出来,通过网络,生成一张图片;所有采样到的vector生成的图片可以得到一个分布。目的是学习到这个网络,使生成图像的分布和真实图像分布接近。
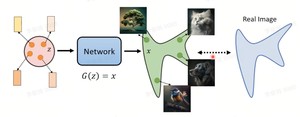
从分布 $z$中采样vector,送入网络 $ heta$产生 $x$,可以得到一个分布 $P_ heta(x)$。真实的训练数据集的分布是 $P_{data}(x)$,从真实的分布中采样 $x^1,x^2,..,x^m$,目的是让从学习到的分布 $P_ heta(x)$产生 $x^i$的概率最大。$P_ heta(x^i)$即分布 $P_ heta$产生 $x^i$的概率。
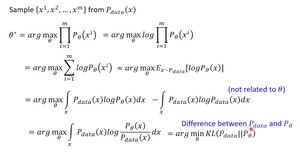
(推导思路:连乘->加log变成连加->转换成分布概率公式->减去真实分布->KL散度)
由上述推导可以得出最大化最大似然估计等价于最小化KL散度。
训练

总体来看,训练过程将图像添加噪声变成噪声图,之后将噪声图和时间步输入模型,模型来预测噪声。
具体来看,首先从图像数据集分布 $q(x_0)$中采样样本 $x_0$,从自然数集合中采样时间步 $t$,从高斯分布中采样噪声 $epsilon$(大小和image相同)。生成添加噪声的新样本图$x_1 = sqrt{baralpha_t}x_0+sqrt{1-baralpha_t} epsilon$。将新样本图和时间步 $t$送入噪声预测模型中,模型预测出噪声 $epsilon_ heta$,预测的噪声和真实的噪声求损失,来更新模型参数。重复上述步骤直至收敛。
推理

总体来说,给定一个噪声图,推理过程每一步预测噪声图的噪声,将噪声图去噪还原成更接近原图的图,之后重复步骤,生成越来越清晰的图像。
具体来看,推理过程首先从高斯分布中采样一个噪声图 $x_T$。
之后从 $t=T$一直到 $t=1$重复 $T$步,每一步首先从高斯分布采样一个噪声 $z$,之后将 $x_t$和时间步 $t$送入噪声预测模型预测出噪声 $epsilon_ heta$,根据预测的噪声和图像 $x_t$以及采样的噪声 $z$用公式求出 $x_{t-1}$。
https://zhuanlan.zhihu.com/p/
训练过程对应前向加噪过程。一步步给图像添加噪音,使其变模糊。当步骤足够多,图像接近一张纯噪声。
$x_0$是从训练图像数据分布 $q(x_0)$中采样的样本。
从第 $x_{t-1}$张图生成第 $x_t$张图的公式: $x_t = sqrt{1-beta_t}x_{t-1}+sqrt{beta_t}epsilon,epsilon sim N(0,1)$,其中 $beta_1,beta_2,…beta_t$是一组人为设定的固定常数,随着 $t$的增加而增大。
令 $alpha_t = 1 - beta_t$,则公式变为 $x_t = sqrt{alpha_t}x_{t-1}+sqrt{1-alpha_t}epsilon$
继续推导,得到
$$begin{align*}x_t &= sqrt{alpha_t}x_{t-1}+sqrt{1-alpha_t}epsilon \&= sqrt{alpha_t}(sqrt{alpha_{t-1}}x_{t-2}+sqrt{1-alpha_{t-1}}epsilon)+sqrt{1-alpha_t}epsilon\&=sqrt{alpha_talpha_{t-1}}x_{t-2}+sqrt{alpha_t(1-alpha_{t-1})}epsilon +sqrt{1-alpha_t}epsilonend{align*}$$
由于正态分布的可加性, $sqrt{alpha_t(1-alpha_{t-1})}epsilon +sqrt{1-alpha_t}epsilon$可以看作:
$X_1 in sqrt{alpha_t(1-alpha_{t-1})}epsilon =N(0,alpha_t(1-alpha_{t-1}))$
$X_2 in sqrt{1-alpha_t}epsilon = N(0,1-alpha_t)$
$X_1+X_2 = N(0,1-alpha_talpha_{t-1})$
即, $sqrt{alpha_t(1-alpha_{t-1})}epsilon +sqrt{1-alpha_t}epsilon = sqrt{1-alpha_talpha_{t-1}}epsilon$
所以, $x_t = sqrt{alpha_talpha_{t-1}}x_{t-2}+sqrt{1-alpha_talpha_{t-1}}epsilon$
数学归纳法,进一步推导得:
$x_t = sqrt{alpha_talpha_{t-1}…alpha_1}x_0 + sqrt{1-alpha_talpha_{t-1}…alpha_1}epsilon$
令 $baralpha_t=alpha_talpha_{t-1}…alpha_1$,则公式进一步化简为
$x_t = sqrt{baralpha_t}x_0+sqrt{1-baralpha_t}epsilon$
从而可以看出,仅仅由 $x_0$即可一步得到 $x_t$。
(推导过程思路:代入 $x_{t-1}$,展开式子,利用正态分布的可加性)
https://zhuanlan.zhihu.com/p/
推理过程即反向去噪过程,目的是根据当前时刻的图片去预测前一时刻的图片,逐步还原成原图。
数学角度来看,即需要我们求出 $p(x_{t-1}|x_t)$,在给定 $x_t$的情况下,预测 $x_{t-1}$的概率分布。(注意,不是预测 $x_{t-1}$,而是预测 $x_{t-1}$的概率分布,由于生成结果需要满足多样性, $x_{t-1}$可能是任何相关的图像,而不是某一个具体的图像。 $x_{t-1}$是某张图的概率可能是最大的,是另一张图的概率较小,但是也不排除会生成。要从分布的角度思考,而不是单一样本的角度来思考)
采用贝叶斯公式计算后验概率:
$P(x_{t-1}|x_t) = frac{P(x_{t-1})P(x_t)}{P(x_t)} = frac{P(x_t|x_{t-1})P(x_{t-1})}{P(x_t)}$
因为推理过程满足马尔可夫假设,$P(x_{t-1}|x_t) = P(x_{t-1}|x_t,x_0)$。(马尔可夫链:状态空间中经过一个状态到另一个状态的转换的随机过程,具备无记忆性,即下一状态的概率分布只能由当前状态决定。所以, $x_{t-1}$只能由 $x_t$决定,和 $x_0$无关,所以等式 $P(x_{t-1}|x_t) = P(x_{t-1}|x_t,x_0)$成立)
$P(x_{t-1}|x_t) = P(x_{t-1}|x_t,x_0) =frac{P(x_t|x_{t-1},x_0)P(x_{t-1},x_0)}{P(x_t|x_0)}$
根据公式 $x_t = sqrt{1-beta_t}x_{t-1}+sqrt{beta_t}epsilon$和 $x_t = sqrt{baralpha_t}x_0+sqrt{1-baralpha_t}epsilon$,得到:
$P(x_t|x_{t-1},x_0) = P(x_t|x_{t-1})=N(x_t;sqrt{1-beta_t}x_{t-1},beta_tI) = N(x_t;sqrt{alpha_t}x_{t-1},(1-alpha_t)I)$
$P(x_{t-1},x_0)=N(x_{t-1};sqrt{baralpha_{t-1}}x_0,(1-baralpha_{t-1})I)$
$P(x_t|x_0)=N(x_t;sqrt{baralpha_t}x_0,(1-baralpha_t)I)$
为此, $P(x_{t-1}|x_t) =frac{P(x_t|x_{t-1},x_0)P(x_{t-1},x_0)}{P(x_t|x_0)} = frac{N(x_t;sqrt{alpha_t}x_{t-1},(1-alpha_t)I)N(x_{t-1};sqrt{baralpha_{t-1}}x_0,(1-baralpha_{t-1})I)}{N(x_t;sqrt{baralpha_t}x_0,(1-baralpha_t)I)}$
由正态分布的概率密度函数: $f(x) = frac{1}{sqrt{2pisigma}}exp(-frac{(x-u)^2}{2sigma^2})$
得到, $P(x_{t-1}|x_t,x_0)propto exp(-frac{1}{2}[frac{(x_t-sqrt{alpha_t}x_{t-1})^2}{1-alpha_t}+frac{(x_{t-1}-sqrt{baralpha_{t-1}}x_0)^2}{1-baralpha_{t-1}}-frac{(x_t-sqrt{baralpha_t}x_0)^2}{1-baralpha_t}]$
由于 $x_{t-1}$是我们关注的变量,整理成 $x_{t-1}$的形式:
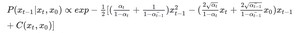
由正态分布满足 $f(x) propto exp -frac{x^2+u^2-2xu}{sigma^2}$,则:
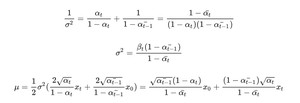
又因为 $x_t = sqrt{baralpha_t}x_0+sqrt{1-baralpha_t}epsilon$,把u里面的 $x_0$换掉,得:
$u = frac{1}{sqrt{alpha_t}}(x_t-frac{1-alpha_t}{sqrt{1-baralpha_t}}epsilon)$
所以, $P(x_{t-1}|x_t) = N(x_{t-1};frac{1}{sqrt{alpha_t}}(x_t-frac{1-alpha_t}{sqrt{1-baralpha_t}}epsilon),frac{(1-alpha_t)(1-baralpha_{t-1})}{1-baralpha_t})$
即基于 $x_t$预测 $x_{t-1}$的分布是一个高斯分布,均值为 $frac{1}{sqrt{alpha_t}}(x_t-frac{1-alpha_t}{sqrt{1-baralpha_t}}epsilon)$,方差为 $frac{(1-alpha_t)(1-baralpha_{t-1})}{1-baralpha_t}$。推理算法中第4行即代表这个分布。
(推导过程思路:贝叶斯公式展开 $P(x_{t-1}|x_t)$->马尔可夫假设添加 $x_0$->正态分布性质进行化简->得到的也是一个正态分布,得到 $u$和 $sigma$,即得出需要学习的分布)
相同和不同点
- 相同之处:
- 前向过程都是将数据转化为一系列潜在表示;反向去噪过程都是把潜在表示生成原图像。
- 训练目标是最大似然的下界
- 不同之处:
- DDPM可以看作是层次化的VAE,从一步到位改成T步到位,一个包含T个隐变量的隐变量模型
- DDPM中的正向过程是固定好的人为设计的encoder,把原图变成噪声图的过程不是学习得到的
- DDPM中潜在噪声图(隐变量)的维度和图像本身相同,而VAE中潜在空间一般会降低维度
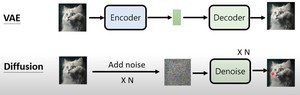
变分下界角度推导VAE和DDPM
变分下界:variational lower bound, VLB
- VAE
推导如下,其中,因为 $int_zq(z|x)dz=1$,所以第一行 $logP_ heta(x)=int_zq(z|x)logP(x)dz$成立。
第二行利用贝叶斯公式展开,分子分母上下添加 $q(z|x)$。
第三行展开,得到右边是一项KL散度,KL散度一定大于等于0,则得到下界。

- DDPM
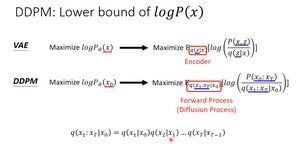
进一步化简:

即优化下面这个式子,让这个式子越大越好:
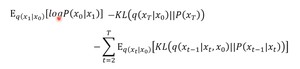
其中该等式第二项是diffusion的前向过程,不是网络学习到的,所以可以不看;第一项和第三项的计算过程很像,以第三项为例,由“推理过程原理部分”推导出 $q(x_{t-1}|x_t,x_0)$是一个高斯分布,满足 $N(frac{1}{sqrt{alpha_t}}(x_t-frac{1-alpha_t}{sqrt{1-baralpha_t}}epsilon),frac{(1-alpha_t)(1-baralpha_{t-1})}{1-baralpha_t})$。为了使最大似然概率更大,则应该使第三项KL散度越小越好,则 $P(x_{t-1}|x_t)$应该尽可能和分布 $N(frac{1}{sqrt{alpha_t}}(x_t-frac{1-alpha_t}{sqrt{1-baralpha_t}}epsilon),frac{(1-alpha_t)(1-baralpha_{t-1})}{1-baralpha_t})$类似。得出和“推理过程原理”部分相同的结论。
扩散模型的核心在于训练噪音预测模型,采用一个基于residual block和attention block的U-Net模型。
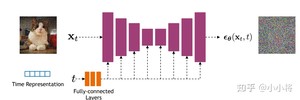
U-Net属于encoder-decoder架构。每个stage包含2个residual block,部分stage还加入了自注意力模块增加网络全局建模能力。添加time embedding模块将时间步编码到网络中(采用和transformer相同的正余弦函数编码方式),具体来说,DDPM在各个残差块都引入了time embedding。
- encoder:逐步压缩图像大小
- decoder:将encoder压缩的特征逐渐恢复,decoder模块中还引入了跳跃连接,即concat了encoder中间得到的同维度特征,有利于网络优化
噪音预测采用MSE平方误差损失。
https://github.com/xiaohu2015/nngen/blob/main/models/diffusion_models/ddpm_mnist.ipynb
训练过程
关键代码:
(1)对batch里每个样本随机采样一个时间步t
(2)预测噪音并计算损失
其中代码 将时间步t和噪声图x_noisy一起送入噪声预测模型中。时间步t嵌入到噪声预测模型中的方式:
- timesteps([b])首先被正余弦位置编码编码([b,model_channels]),之后经过2个linear层([b,model_channels*4])
- 正余弦位置编码
和transformer类似,transformer中的位置编码函数:
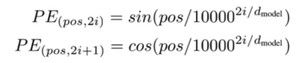
相当于偶数位置采用sin函数,奇数位置采用cos函数。其中公共部分可以如下推导:
$10000^{frac{2i}{d}} = e^{log(10000^{frac{2i}{d}})} = e^{frac{2i}{d}log1000}$
此外,ddpm中采用每个位置的dim维度中前一半维度使用cos编码,后一半维度使用sin编码的方式。
- time_embed层:
- 时间步信息在每个残差块注入
采用将时间步嵌入和图像特征直接相加进行融合的方式
推理过程
(1)生成纯噪音图像
(2)循环timesteps个时间步,逐渐更新图像
(3)每个时间步内操作
- 整体流程
首先计算均值和对数方差;采样噪音,其中因为噪音在最后一步的时候为0,所以使用一个nonzero_mask矩阵来判断
- “计算 $p(x_{t-1}|x_t)$的均值和方差”步骤
推理算法中给出的公式如下,实际实现时采用的公式是未将 $x_0$替换的版本,并且对 $x_0$做了clip操作(将 $x_0$中的元素限制在-1和1之间),使用的是对数方差再取指数e(对数方差限制最小值为0):

可视化结果
- 生成结果

- 逐步结果

- 使用重参数化公式 $x_t =sqrt{baralpha_t}x_0+sqrt{1-baralpha_t}epsilon$一步计算得到 $x_0$的结果
https://www.zhihu.com/question/
可以看出,直接一步计算得到 $x_0$的结果是不行的。正向是一个加噪的过程,可以粗糙一点;但是逆向过程是一个复原图像的过程,需要更精细,否则误差会非常大。

DDPM的推理速度过慢,需要设置较长的扩散步数才能得到好的效果。其无法避免迭代过程,因为其本身是一个马尔可夫链,即前后时刻数据有非常紧密的绑定关系,无法进行跳跃预测。
DDIM(denoising diffusion implicit models)和DDPM有相同的训练目标,但是不再限制扩散过程必须是一个马尔可夫链,使得DDIM可以采用更大的采样步数来加速生成过程。DDIM的另外一个特点是当 $sigma$取值为0时,从一个随机噪音生成样本的过程是一个确定的过程(中间没有加入随机噪音)。DDIM无需重新训练DDPM(无需改变前向加噪过程),只对采样器进行修改即可,修改后的采样器能够大幅增加采样速度。
由“变分下界推导VAE和DDPM”一节可以看出优化的终极目标是去拟合概率分布 $P(x_{t-1}|x_0,x_t)$,公式:
$P(x_{t-1}|x_t,x_0) = frac{P(x_t|x_{t-1},x_0)P(x_{t-1}|x_0)}{P(x_t|x_0)}$
不再假设它是一个马尔可夫链,使用待定系数法,假设 $P(x_{t-1}|x_t,x_0)$满足正态分布:
$P(x_{t-1}|x_t,x_0) sim N(kx_0+mx_t,sigma^2I)$
则 $x_{t-1} = kx_0+mx_t+sigmaepsilon$。
又由于前向过程公式 $x_t = sqrt{baralpha_t}x_0+sqrt{1-baralpha_t}epsilon$,
得: $x_{t-1} = kx_0+m(sqrt{baralpha_t}x_0+sqrt{1-baralpha_t}epsilon)+sigmaepsilon=(k+msqrt{baralpha_t})x_0+msqrt{1-baralpha_t}epsilon+sigmaepsilon$
由正态分布的可加性,得 $x_{t-1}=(k+msqrt{baralpha_t})x_0+sqrt{m^2(1-baralpha_t)+sigma^2}epsilon$
又 $x_{t-1} = sqrt{baralpha_{t-1}}x_0+sqrt{1-baralpha_{t-1}}epsilon$,对应系数相同,得到:
$k+msqrt{baralpha_t} = sqrt{baralpha_{t-1}}$, $m^2(1-baralpha_t)+sigma^2=1-baralpha_{t-1}$
解方程组,得:
因此, $P(x_{t-1}|x_t,x_0)=N(sqrt{baralpha_{t-1}}x_0+sqrt{1-baralpha_{t-1}-sigma^2}frac{x_t-sqrt{baralpha_t}x_0}{sqrt{1-baralpha_t}},sigma^2I)$
用 $x_t$替换 $x_0$,得到:
$x_{t-1} = sqrt{baralpha_{t-1}}(frac{x_t-sqrt{1-baralpha_t}epsilon_ heta(x_t)}{sqrt{baralpha_t}})+sqrt{1-baralpha_{t-1}-sigma^2}epsilon_ heta(x_t)+sigmaepsilon$
由于推导过程中没有使用马尔可夫性质,所以可以不满足马尔可夫要求, $t-1$可以替换为 $prev$, $x_t$和 $x_{prev}$可以相隔多个迭代步数。
(推导思路:使用待定系数法假设它满足一个分布,之后结合前向过程公式可以推导出系数)
$sigma$的取值不会影响推导式子的成立。
- 当 $sigma = 0$,采样过程不再具有随机性,每个 $x_T$对应了确定的 $x_0$。
- 若 $sigma = frac{1-baralpha_{t-1}}{1-baralpha_t}beta_t$( $= frac{1-baralpha_{t-1}}{1-baralpha_t}(1-frac{baralpha_t}{baralpha_{t-1}})$),则是DDPM中采用的方差,此时DDIM等价于DDPM。


https://github.com/xiaohu2015/nngen/blob/main/models/diffusion_models/ddim_mnist.ipynb
- 训练过程和ddpm一致
- 测试过程函数:
(1)因为ddim可以隔很多步进行采样,所以时间序列不再是[499,498,497,496],而是类似[476,451,426,376,…]的间隔序列,可以采用均匀采样的方式采样间隔的时间步:
(2)采样噪声图
(3)开始迭代还原图像,根据公式 $x_{t-1} = sqrt{baralpha_{t-1}}(frac{x_t-sqrt{1-baralpha_t}epsilon_ heta(x_t)}{sqrt{baralpha_t}})+sqrt{1-baralpha_{t-1}-sigma^2}epsilon_ heta(x_t)+sigmaepsilon$,其中方差的公式采用 $sigma = etasqrt{frac{1-baralpha_{t-1}}{1-baralpha_t}}sqrt{1-frac{baralpha_t}{baralpha_{t-1}}}$
- 20步,ddim_eta=0时的生成效果:

采样一致性(sample consistency)
当方差为0时,生成过程是确定的,只受 $x_T$影响。给定不同的 $x_T$,不同的采样步数下生成的图片都是类似的, $x_T$可以看作生成图片的隐编码信息。(在实际生成图片时可以控制 $x_T$不变,设置较小的采样步数,若生成的图片是想要的,再用更大的步数生成更精细的图片)。

版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/3799.html