
目录
1. 引言与背景
2. DQN定理
3. 算法原理
4. 算法实现
5. 优缺点分析
优点:
缺点:
6. 案例应用
7. 对比与其他算法
8. 结论与展望
1. 引言与背景
强化学习作为机器学习的一个重要分支,致力于通过智能体与环境的交互学习最优行为策略。在传统的强化学习方法中,如Q-Learning、SARSA等,通常使用表格或简单函数近似来表示Q值函数。然而,对于高维、连续或复杂状态空间的问题,这些方法的表达能力和泛化能力受到严重限制。Deep Q-Networks (DQN)的提出,首次将深度学习与Q-Learning相结合,通过深度神经网络对Q值函数进行高效且灵活的近似,极大地拓宽了强化学习在复杂环境中的应用范围,成为深度强化学习领域的一大里程碑。
2. DQN定理
DQN算法的理论基础依然建立在Q-Learning的贝尔曼方程之上,但其核心在于使用深度神经网络作为Q值函数的近似器。对于任意状态s和动作a,DQN的目标是学习一个函数Q(s, a; θ),其中θ代表神经网络的参数,使得其输出尽可能接近真实的Q值。
Theorem 1 (Bellman Optimality Equation for Q-Learning): 对于任意状态s、动作a和下一个状态s',存在最优Q函数Q*(s, a)满足:
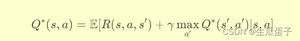
DQN通过最小化Q值网络输出与上述贝尔曼方程右侧目标值之间的均方误差,进行网络参数更新:
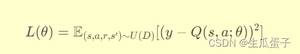
其中是目标Q值,代表目标网络的参数,D是经验回放缓冲区,U(D)表示从D中均匀采样经验。
3. 算法原理
DQN算法遵循以下主要步骤:
Step 1: 初始化深度Q网络(DQN)和目标网络,两者具有相同的架构但参数独立。将经验(状态、动作、奖励、新状态)存储在经验回放缓冲区D中。
Step 2: 在每个时间步t,智能体根据当前状态st和DQN选择动作at。执行动作后,观察到新状态st+1、奖励rt。
Step 3: 将经验(st, at, rt, st+1)存入经验回放缓冲区D。
Step 4: 从D中采样一批经验,计算每个经验的目标Q值yt,根据目标Q值和DQN的输出计算损失函数L(θ),使用反向传播更新DQN参数θ。
Step 5: 定期(如每隔固定步数)将DQN的参数复制到目标网络,保持目标Q值的稳定性。
Step 6: 重复步骤2-5,直至达到训练终止条件。
4. 算法实现
以下是一个使用PyTorch实现DQN算法的简单示例(以OpenAI Gym的CartPole-v0环境为例):
Python
- 定义DQN网络:
- 创建一个名为的类,继承自,用于构建深度Q网络。该网络包含三层全连接层(两层隐藏层和一层输出层),每层之间使用ReLU激活函数。
- 定义Agent类:
- 创建一个名为的类,负责实现DQN算法的整体逻辑。该类包含以下主要属性:
- : 存储环境对象,用于与智能体进行交互。
- 和 : 分别为深度Q网络和目标网络,具有相同的网络结构但参数独立。
- : 使用Adam优化器对DQN网络进行优化。
- : 一个列表,用于存储智能体与环境交互产生的经验(状态、动作、奖励、新状态、是否结束)。
- 类还包含以下主要方法:
- : 根据当前状态,使用DQN网络选择动作。将状态转换为张量,计算Q值,返回最大Q值对应的动作索引。
- : 从经验回放缓冲区中采样一批经验,计算目标Q值,计算损失,反向传播更新DQN网络参数。若满足条件,同步DQN网络参数到目标网络。
- : 执行一个完整的游戏回合。初始化状态,循环执行动作,接收环境反馈,将经验存入回放缓冲区,直到游戏结束。最后调用方法进行学习。
- : 调用方法多次(由参数指定),进行多轮训练,并在每轮结束后打印当前回合的奖励。
- 创建一个名为的类,负责实现DQN算法的整体逻辑。该类包含以下主要属性:
- 实例化Agent对象:
- 创建一个对象,传入环境和其他相关参数(如折扣因子、批量大小、学习率、目标网络更新频率等)。
- 训练Agent:
- 调用方法,开始进行DQN算法的训练。在指定数量()的回合中,智能体与环境进行交互,积累经验并进行学习。每回合结束后,打印该回合的奖励。
综上所述,该代码首先定义了DQN网络和Agent类,然后实例化一个Agent对象并指定环境及其他参数,最后调用方法进行DQN算法的训练。在训练过程中,智能体与环境进行多轮交互,通过选择动作、积累经验、学习更新Q网络参数,逐渐学习到如何在CartPole环境中保持杆子竖直的最优策略。
5. 优缺点分析
优点:
- 高效表达能力:通过深度神经网络,DQN能够对高维、连续或复杂状态空间的Q值函数进行高效且灵活的近似,大大增强了模型的表达能力和泛化能力。
- 经验重用:使用经验回放缓冲区,使得智能体可以反复学习过去的经验,提高了数据利用率,有助于稳定学习过程。
- 离线学习:DQN采用离线批量更新方式,避免了在线更新时目标Q值的不稳定性,提高了算法的收敛性。
缺点:
- 计算资源需求:深度神经网络的训练需要较大的计算资源,包括内存和计算力,尤其是在大规模或复杂环境中。
- 收敛速度:DQN的收敛速度可能较慢,尤其是对于探索效率较低的问题,可能需要较长的训练时间才能达到理想性能。
- 对超参数敏感:DQN对学习率、批量大小、目标网络更新频率等超参数较为敏感,需要仔细调整以获得良好性能。
6. 案例应用
Atari游戏:DQN在Atari 2600游戏中取得了突破性成果,能够在许多经典游戏中达到人类专业玩家的水平,如Breakout、Pong、Space Invaders等。
机器人控制:DQN应用于机器人运动控制任务,如机械臂抓取、无人机飞行路径规划等,通过学习在复杂环境中的最优动作序列,实现自主决策与控制。
推荐系统:在个性化推荐场景中,DQN可以学习用户对不同推荐策略的长期反馈,优化推荐策略以最大化用户满意度和平台收益。
7. 对比与其他算法
与Q-Learning/SARSA:
- Q-Learning:DQN与Q-Learning都基于Q-learning算法的基本思想,即通过贝尔曼方程更新Q值以逼近最优Q函数。两者的主要区别在于Q值的近似方式。Q-Learning通常使用表格(对于有限状态空间)或简单的函数近似(如线性函数)来存储和更新Q值。而对于具有高维、连续或复杂状态空间的问题,这样的表示方式难以有效处理。
DQN则通过深度神经网络对Q值进行近似,神经网络的层次结构和非线性激活函数使其能够捕获复杂状态和动作间的关系,从而适应高维、连续或复杂状态空间。这种近似方式极大地扩展了Q-learning在处理复杂问题时的能力。
- SARSA:与SARSA相比,DQN同样采用Q-learning的更新机制,即在更新当前状态-动作对的Q值时,考虑的是下一步状态的最大Q值。而SARSA在更新时使用的是下一步状态实际采取的动作所对应的Q值。这意味着DQN在更新时更偏向于贪婪学习,倾向于最大化期望回报,这可能使得它在某些情况下更快收敛,但也可能因为过度关注当前最优而忽视潜在的最优路径,尤其是在探索不足的情况下。
与Double DQN/DDPG/TD3:
- Double DQN:Double DQN是对DQN的改进,旨在解决DQN中由于使用相同的网络来选择动作和评估动作价值导致的过估计问题。Double DQN引入了两个网络:一个用于选择下一步最优动作,另一个(通常是目标网络)用于评估该动作的价值。这样分离的选择和评估过程有助于减少Q值的过估计,从而提高学习的稳定性。
- DDPG(Deep Deterministic Policy Gradient):DDPG是针对连续动作空间问题设计的算法,它结合了DQN的深度学习架构和Deterministic Policy Gradient(DPG)算法的思想。DDPG使用一个Actor网络(确定性策略网络)直接输出动作,而一个Critic网络(类似于DQN的Q网络)评估当前状态-动作对的价值。DDPG适用于处理连续动作空间的环境,而DQN主要面向离散动作空间。
- TD3(Twin Delayed Deep Deterministic Policy Gradients):TD3是在DDPG基础上进一步改进的算法,旨在解决DDPG中存在的过估计、动作抖动等问题。TD3引入了双Critic网络(类似Double DQN中的双网络结构)和延迟更新策略,以减小估计偏差和提高学习稳定性。此外,TD3还通过目标动作平滑化和Clip双重Q-learning等技巧进一步抑制了过估计。
总结来说,DQN相对于Q-Learning和SARSA,通过深度神经网络实现了对复杂状态空间的有效处理;而与Double DQN、DDPG、TD3等算法相比,它们是DQN在特定问题(如过估计问题、连续动作空间问题)上的改进版本,通过引入额外的技术手段提高了学习性能和稳定性。这些算法在实际应用中可根据具体任务特点和环境特性进行选择和调整。
8. 结论与展望
结论:
Deep Q-Networks (DQN)作为深度强化学习的开创性工作,成功地将深度学习的强大表征能力与Q-learning的强化学习框架相结合,克服了传统强化学习方法在处理高维、连续或复杂状态空间问题时的局限性。DQN通过深度神经网络对Q值函数进行高效近似,利用经验回放缓冲区实现经验重用,以及引入目标网络保证学习的稳定性,展现出了在各类复杂环境(如Atari游戏、机器人控制、推荐系统等)中学习最优策略的强大能力。
尽管DQN在实践中取得了显著成果,但也存在一些挑战,如对计算资源的需求较高、收敛速度可能较慢、对超参数敏感等。针对这些问题,后续研究提出了诸如Double DQN、DDPG、TD3等改进算法,通过修正Q值估计、处理连续动作空间、增强学习稳定性等手段,进一步优化了DQN的性能。
展望:
随着深度强化学习领域的持续发展,DQN及其衍生算法的未来研究与应用有望在以下几个方面取得进展:
- 算法优化与改进:继续探索新的网络架构、优化方法、正则化技术等,以提高DQN的收敛速度、稳定性和泛化能力。例如,研究新型深度学习模型(如Transformer、Graph Neural Networks等)在DQN中的应用,或者结合元学习、自监督学习等前沿技术提升学习效率。
- 环境适应性:针对不同类型、不同复杂度的环境,开发适应性强、泛化性能好的DQN变种。例如,研究如何在未知、动态、部分可观测或非马尔科夫环境中有效地应用DQN,或者针对特定领域的任务(如自动驾驶、游戏AI、机器人操作等)定制化设计DQN模型。
- 理论深化:深化对DQN学习过程的理解,揭示其内在工作机制与收敛性质,为算法设计与调优提供理论指导。例如,研究DQN的收敛条件、样本复杂度、最优策略质量保证等问题,或者探索DQN与其它强化学习框架(如 actor-critic、蒙特卡洛方法等)的融合与比较。
- 实际应用推广:推动DQN在更多实际场景中的落地应用,如工业自动化、能源管理、医疗决策、金融交易等。这需要结合具体领域的知识,设计针对性的环境建模、状态表示、奖励函数等,同时考虑现实约束(如延迟、通信成本、安全性等)对算法设计的影响。
总的来说,Deep Q-Networks作为深度强化学习的基石之一,其理论研究与应用实践仍有广阔的发展空间。随着算法的持续优化、环境适应性的提升以及理论理解的深化,DQN将在未来持续推动强化学习乃至人工智能领域的技术创新与应用拓展。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/4072.html