
源码+官方文档
JUC是 java util concurrent
面试高频问JUC~!
java.util 是Java的一个工具包~
业务:普通的线程代码 Thread
Runnable: 没有返回值、效率相比于Callable 相对较低!
进程:一个程序,.EXE Music.EXE;数据+代码+pcb
一个进程可以包含多个线程,至少包含一个线程!
Java默认有几个线程?2个线程! main线程、GC线程
线程:开了一个进程Typora,写字,等待几分钟会进行自动保存(线程负责的)
对于Java而言:Thread、Runable、Callable进行开启线程的,我们之前。
提问?JAVA真的可以开启线程吗? 开不了的!
Java是没有权限去开启线程、操作硬件的,这是一个native的一个本地方法,它调用的底层的C++代码。
并发、并行
并发: 多线程操作同一个资源。
- CPU 只有一核,模拟出来多条线程,天下武功,唯快不破。那么我们就可以使用CPU快速交替,来模拟多线程。
并行: 多个人一起行走
- CPU多核,多个线程可以同时执行。 我们可以使用线程池!
并发编程的本质:充分利用CPU的资源!
线程有几个状态?
线程的状态:6个状态
wait/sleep的区别
1、来自不同的类
wait => Object
sleep => Thread
一般情况企业中使用休眠是:
2、关于锁的释放
wait 会释放锁;
sleep睡觉了,不会释放锁;
3、使用的范围是不同的
wait 必须在同步代码块中;
sleep 可以在任何地方睡;
4、是否需要捕获异常
wait是不需要捕获异常;
sleep必须要捕获异常;
传统的Synchronized
Lock接口


公平锁: 十分公平,必须先来后到~;
非公平锁: 十分不公平,可以插队;(默认为非公平锁)
Synchronized 和 Lock区别
- 1、Synchronized 内置的Java关键字,Lock是一个Java类
- 2、Synchronized 无法判断获取锁的状态,Lock可以判断
- 3、Synchronized 会自动释放锁,lock必须要手动加锁和手动释放锁!可能会遇到死锁
- 4、Synchronized 线程1(获得锁->阻塞)、线程2(等待);
lock就不一定会一直等待下去,lock会有一个trylock去尝试获取锁,不会造成长久的等待。
- 5、Synchronized 是可重入锁,不可以中断的,非公平的;Lock,可重入的,可以判断锁,可以自己设置公平锁和非公平锁;
- 6、Synchronized 适合锁少量的代码同步问题,Lock适合锁大量的同步代码;
锁到底是什么? 如何判断锁的是谁?
Synchronized wait notify可以实现,该方法是传统版本;
我们这次使用lock版本
Synchronized版本
问题存在,A线程B线程,现在如果我有四个线程A B C D!

解决方案: if 改为while即可,防止虚假唤醒
这样就不存在问题了:
JUC版本的生产者和消费者问题
await、signal 替换 wait、notify
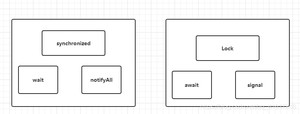
通过Lock找到Condition

Condition的优势:精准的通知和唤醒的线程!
如果我们要指定通知的下一个进行顺序怎么办呢? 我们可以使用Condition来指定通知进程~
如何判断锁的是谁!锁到底锁的是谁?
锁会锁住:对象、Class
深刻理解我们的锁
- 问题1:
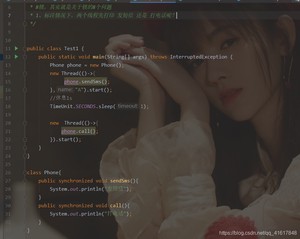
结果是:先发短信,如何再打电话!
为什么? 如果你认为是顺序在前? 这个答案是错误的!
- 问题2:
我们再来看:我们让发短信 延迟4s

现在结果是什么呢?
结果:还是先发短信,然后再打电话!
why?
原因:并不是顺序执行!是因为synchronized 锁的对象是方法的调用!对于两个方法用的是同一个锁,谁先拿到谁先执行!另外一个则等待!
- 问题3:
如果我们添加一个普通方法,那么先执行哪一个呢?
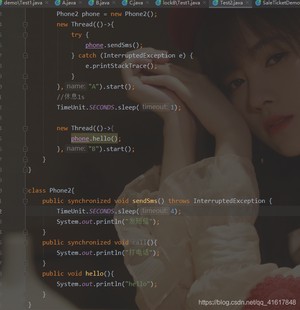
答案是:先执行hello,然后再执行发短信!原因是hello是一个普通方法,不受synchronized锁的影响,但是我发现,如果我把发短信里面的延迟4秒去掉,那么就会顺序执行,先执行发短信然后再执行hello,原因应该是顺序执行的原因吧,不是太理解。
- 问题4:
如果我们使用的是两个对象,一个调用发短信,一个调用打电话,那么整个顺序是怎么样的呢?
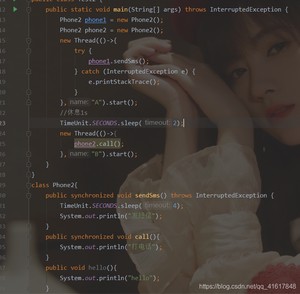
答案是:先打电话,后发短信。原因:在发短信方法中延迟了4s,又因为synchronized锁的是对象,但是我们这使用的是两个对象,所以每个对象都有一把锁,所以不会造成锁的等待。正常执行
- 问题5,6:
如果我们把synchronized的方法加上static变成静态方法!那么顺序又是怎么样的呢?
(1)我们先来使用一个对象调用两个方法!
答案是:先发短信,后打电话
(2)如果我们使用两个对象调用两个方法!
答案是:还是先发短信,后打电话
原因是什么呢? 为什么加了static就始终前面一个对象先执行呢!为什么后面会等待呢?
原因是:对于static静态方法来说,对于整个类Class来说只有一份,对于不同的对象使用的是同一份方法,相当于这个方法是属于这个类的,如果静态static方法使用synchronized锁定,那么这个synchronized锁会锁住整个对象!不管多少个对象,对于静态的锁都只有一把锁,谁先拿到这个锁就先执行,其他的进程都需要等待!
- 问题7:
如果我们使用一个静态同步方法、一个同步方法、一个对象调用顺序是什么?

明显答案是:先打电话,后发短信了。
因为一个锁的是Class类模板,一个锁的是对象调用者。后面那个打电话不需要等待发短信,直接运行就可以了。
- 问题8:
如果我们使用一个静态同步方法、一个同步方法、两个对象调用顺序是什么呢?

当然答案是:先打电话、后发短信!
因为两个对象,一样的原因:两把锁锁的不是同一个东西,所以后面的第二个对象不需要等待第一个对象的执行。
小结
new 出来的 this 是具体的一个对象
static Class 是唯一的一个模板
List不安全
我们来看一下List这个集合类:
会造成:
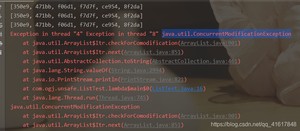
ArrayList 在并发情况下是不安全的!
解决方案:
1、切换成Vector就是线程安全的啦!
2、使用Collections.synchronizedList(new ArrayList<>());
3、使用JUC中的包:List arrayList = new CopyOnWriteArrayList<>();
CopyOnWriteArrayList:写入时复制! COW 计算机程序设计领域的一种优化策略
多个线程调用的时候,list,读取的时候,固定的,写入(存在覆盖操作);在写入的时候避免覆盖,造成数据错乱的问题;
CopyOnWriteArrayList比Vector厉害在哪里?
Vector底层是使用synchronized关键字来实现的:效率特别低下。
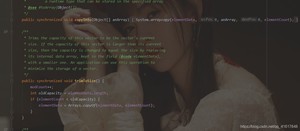
CopyOnWriteArrayList使用的是Lock锁,效率会更加高效!

Set不安全

和List、Set同级的还有一个BlockingQueue 阻塞队列;
Set和List同理可得: 多线程情况下,普通的Set集合是线程不安全的;
解决方案还是两种:
- 使用Collections工具类的synchronized包装的Set类
- 使用CopyOnWriteArraySet 写入复制的JUC解决方案
HashSet底层是什么?
hashSet底层就是一个HashMap;
Map不安全
回顾map的基本操作:
默认加载因子是0.75,默认的初始容量是16
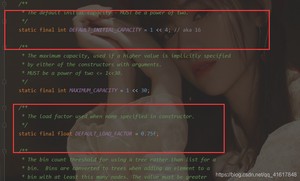
同样的HashMap基础类也存在并发修改异常!
结果同样的出现了:异常java.util.ConcurrentModificationException 并发修改异常
解决方案:
- 使用Collections.synchronizedMap(new HashMap<>());处理;
- 使用ConcurrentHashMap进行并发处理
TODO:研究ConcurrentHashMap底层原理:
这里我们可以直接去研究一下,这个也是相当重要的。
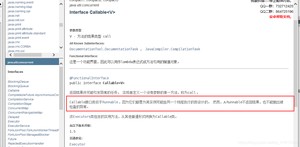
1、可以有返回值;
2、可以抛出异常;
3、方法不同,run()/call()
代码测试
传统使用线程方式:
使用Callable进行多线程操作:
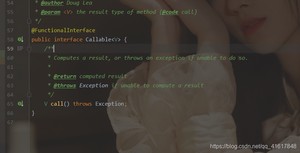
Calleable 泛型T就是call运行方法的返回值类型;
但是如何使用呢?
Callable怎么放入到Thread里面呢?
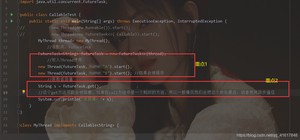
源码分析:
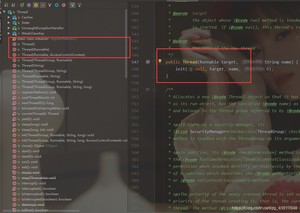
对于Thread运行,只能传入Runnable类型的参数;
我们这是Callable 怎么办呢?
看JDK api文档:
在Runnable里面有一个叫做FutureTask的实现类,我们进去看一下。
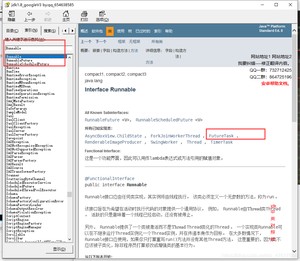
FutureTask中可以接受Callable参数;
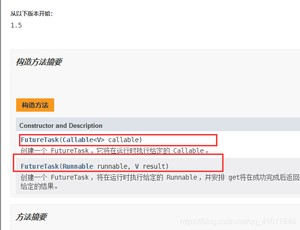
这样我们就可以先把Callable 放入到FutureTask中, 如何再把FutureTask 放入到Thread就可以了。
这样我们就可以使用Callable来进行多线程编程了,并且我们发现可以有返回值,并且可以抛出异常。

注意两个重点:
8.1 CountDownLatch
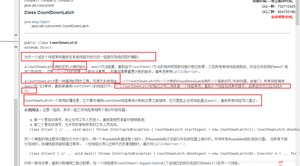
其实就是一个减法计数器,对于计数器归零之后再进行后面的操作,这是一个计数器!
主要方法:
- countDown 减一操作;
- await 等待计数器归零。
await等待计数器为0,就唤醒,再继续向下运行。
8.2 CyclickBarrier

其实就是一个加法计数器;
8.3 Semaphore
Semaphore:信号量
抢车位:
3个车位 6辆车:
原理:
semaphore.acquire()获得资源,如果资源已经使用完了,就等待资源释放后再进行使用!
semaphore.release()释放,会将当前的信号量释放+1,然后唤醒等待的线程!
作用: 多个共享资源互斥的使用! 并发限流,控制最大的线程数!
先对于不加锁的情况:
如果我们做一个我们自己的cache缓存。分别有写入操作、读取操作;
我们采用五个线程去写入,使用十个线程去读取。
我们来看一下这个的效果,如果我们不加锁的情况!
运行效果如下:
所以如果我们不加锁的情况,多线程的读写会造成数据不可靠的问题。
我们也可以采用synchronized这种重量锁和轻量锁 lock去保证数据的可靠。
但是这次我们采用更细粒度的锁:ReadWriteLock 读写锁来保证
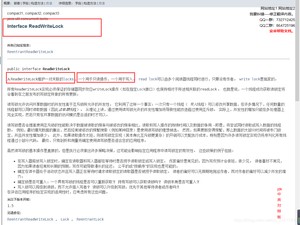
运行结果如下:
阻塞
队列

阻塞队列jdk1.8文档解释:
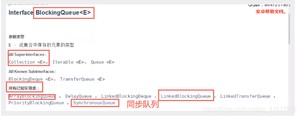
BlockingQueue
blockingQueue 是Collection的一个子类;
什么情况我们会使用 阻塞队列呢?
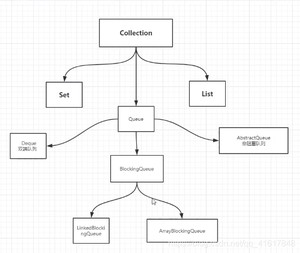
整个阻塞队列的家族如下:Queue以下实现的有Deque、AbstaractQueue、BlockingQueue;
BlockingQueue以下有Link链表实现的阻塞队列、也有Array数组实现的阻塞队列
如何使用阻塞队列呢?
操作:添加、移除
但是实际我们要学的有:
四组API
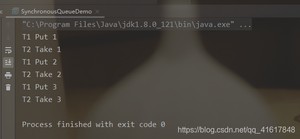
SynchronousQueue同步队列
同步队列 没有容量,也可以视为容量为1的队列;
进去一个元素,必须等待取出来之后,才能再往里面放入一个元素;
put方法 和 take方法;
Synchronized 和 其他的BlockingQueue 不一样 它不存储元素;
put了一个元素,就必须从里面先take出来,否则不能再put进去值!
并且SynchronousQueue 的take是使用了lock锁保证线程安全的。
线程池:三大方法、7大参数、4种拒绝策略
池化技术
程序的运行,本质:占用系统的资源!我们需要去优化资源的使用 ===> 池化技术
线程池、JDBC的连接池、内存池、对象池 等等。。。。
资源的创建、销毁十分消耗资源
池化技术:事先准备好一些资源,如果有人要用,就来我这里拿,用完之后还给我,以此来提高效率。
线程池的好处:
1、降低资源的消耗;
2、提高响应的速度;
3、方便管理;
线程复用、可以控制最大并发数、管理线程;
线程池:三大方法
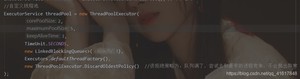
- ExecutorService threadPool = Executors.newSingleThreadExecutor();//单个线程
- ExecutorService threadPool2 = Executors.newFixedThreadPool(5); //创建一个固定的线程池的大小
- ExecutorService threadPool3 = Executors.newCachedThreadPool(); //可伸缩的
7大参数
源码分析
本质:三种方法都是开启的ThreadPoolExecutor
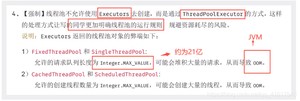
阿里巴巴的Java操作手册中明确说明:对于Integer.MAX_VALUE初始值较大,所以一般情况我们要使用底层的ThreadPoolExecutor来创建线程池。
业务图
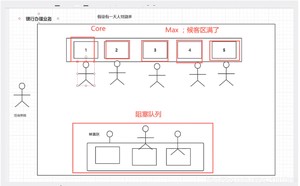
手动创建线程池
// todo
拒绝策略4种
(1)new ThreadPoolExecutor.AbortPolicy(): //该拒绝策略为:银行满了,还有人进来,不处理这个人的,并抛出异常
超出最大承载,就会抛出异常:队列容量大小+maxPoolSize
(2)new ThreadPoolExecutor.CallerRunsPolicy(): //该拒绝策略为:哪来的去哪里 main线程进行处理
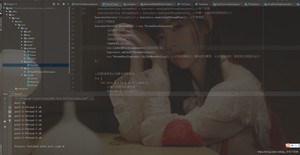
(3)new ThreadPoolExecutor.DiscardPolicy(): //该拒绝策略为:队列满了,丢掉异常,不会抛出异常。
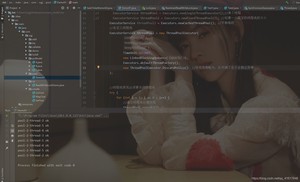
(4)new ThreadPoolExecutor.DiscardOldestPolicy(): //该拒绝策略为:队列满了,尝试去和最早的进程竞争,不会抛出异常
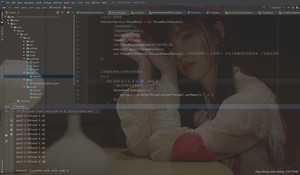
小结和拓展
如何去设置线程池的最大大小如何去设置?
CPU密集型和IO密集型!
1、CPU密集型:电脑的核数是几核就选择几;选择maximunPoolSize的大小
我们可以使用代码来来获取逻辑处理器数量。
于是cpu密集型的写法如下:

2、I/O密集型:
在程序中有15个大型任务,io十分占用资源;I/O密集型就是判断我们程序中十分耗I/O的线程数量,大约是最大I/O数的一倍到两倍之间。
新时代的程序员:lambda表达式、链式编程、函数式接口、Stream流式计算
函数式接口:只有一个方法的接口
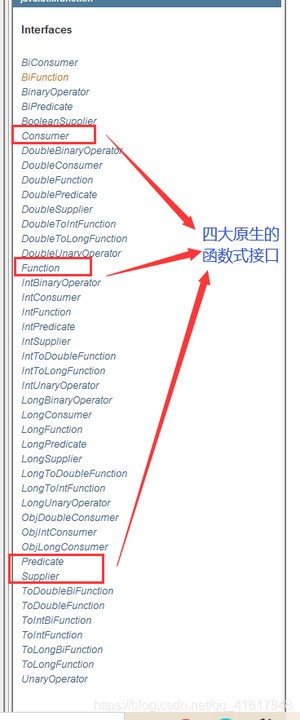
函数型接口可以使用lambda表达式;
代码测试:
Function函数型接口
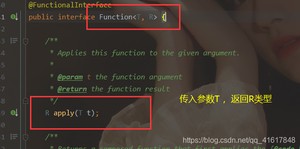
Predicate断定型接口

Consummer 消费型接口

Supplier供给型接口

什么是Stream流式计算?
存储+计算!
存储:集合、MySQL
计算:流式计算~
=== 链式编程 ===
什么是ForkJoin?
ForkJoin 在JDK1.7,并行执行任务!提高效率~。在大数据量速率会更快!
大数据中:MapReduce 核心思想->把大任务拆分为小任务!
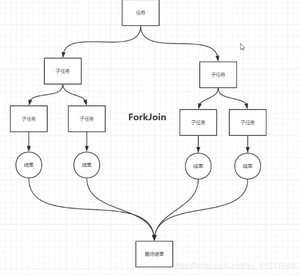
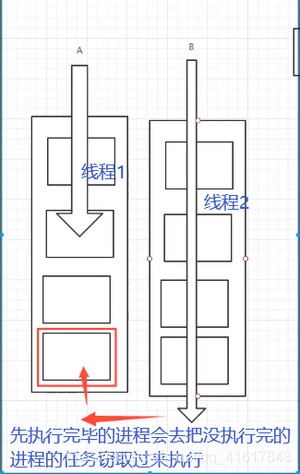
ForkJoin 特点: 工作窃取!
实现原理是:双端队列!从上面和下面都可以去拿到任务进行执行!
如何使用ForkJoin?
- 1、通过ForkJoinPool来执行
- 2、计算任务 execute(ForkJoinTask<?> task)
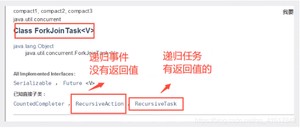
- 3、计算类要去继承ForkJoinTask;
ForkJoin的计算类!
测试类!

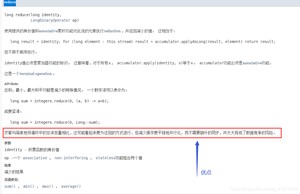
.parallel().reduce(0, Long::sum)使用一个并行流去计算整个计算,提高效率。
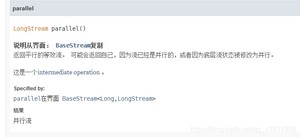
reduce方法的优点:
Future 设计的初衷:对将来的某个事件结果进行建模!
其实就是前端 --> 发送ajax异步请求给后端
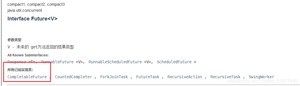
但是我们平时都使用CompletableFuture
(1)没有返回值的runAsync异步回调
(2)有返回值的异步回调supplyAsync
whenComplete: 有两个参数,一个是t 一个是u
T:是代表的 正常返回的结果;
U:是代表的 抛出异常的错误信息;
如果发生了异常,get可以获取到exceptionally返回的值;
请你谈谈你对Volatile 的理解
Volatile 是 Java 虚拟机提供 轻量级的同步机制
1、保证可见性
2、不保证原子性
3、禁止指令重排
什么是JMM?
JMM:JAVA内存模型,不存在的东西,是一个概念,也是一个约定!
关于JMM的一些同步的约定:
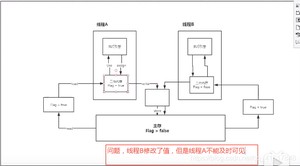
1、线程解锁前,必须把共享变量立刻刷回主存;
2、线程加锁前,必须读取主存中的最新值到工作内存中;
3、加锁和解锁是同一把锁;
线程中分为 工作内存、主内存
8种操作:
- Read(读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用;
- load(载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中;
- Use(使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令;
- assign(赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中;
- store(存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用;
- write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中;
- lock(锁定):作用于主内存的变量,把一个变量标识为线程独占状态;
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定;
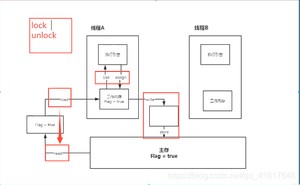
JMM对这8种操作给了相应的规定:
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
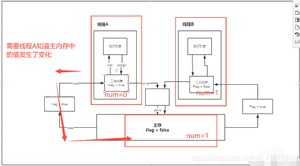
遇到问题:程序不知道主存中的值已经被修改过了!;
1、保证可见性
2、不保证原子性
原子性:不可分割;
线程A在执行任务的时候,不能被打扰的,也不能被分割的,要么同时成功,要么同时失败。
如果不加lock和synchronized ,怎么样保证原子性?
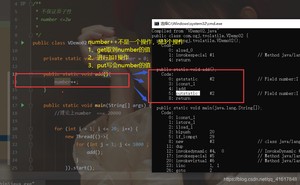
解决方法:使用JUC下的原子包下的class;
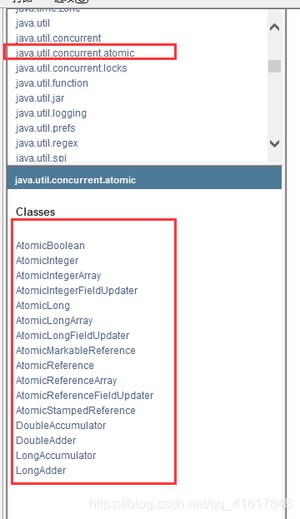
代码如下:
这些类的底层都直接和操作系统挂钩!是在内存中修改值。
Unsafe类是一个很特殊的存在;
原子类为什么这么高级?
3、禁止指令重排
什么是指令重排?
我们写的程序,计算机并不是按照我们自己写的那样去执行的
源代码–>编译器优化重排–>指令并行也可能会重排–>内存系统也会重排–>执行
处理器在进行指令重排的时候,会考虑数据之间的依赖性!
可能造成的影响结果:前提:a b x y这四个值 默认都是0
正常的结果: x = 0; y =0;
可能在线程A中会出现,先执行b=1,然后再执行x=a;
在B线程中可能会出现,先执行a=2,然后执行y=b;
那么就有可能结果如下:x=2; y=1.
volatile可以避免指令重排:
volatile中会加一道内存的屏障,这个内存屏障可以保证在这个屏障中的指令顺序。
内存屏障:CPU指令。作用:
1、保证特定的操作的执行顺序;
2、可以保证某些变量的内存可见性(利用这些特性,就可以保证volatile实现的可见性)
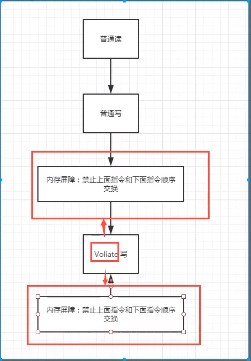
总结
- volatile可以保证可见性;
- 不能保证原子性
- 由于内存屏障,可以保证避免指令重排的现象产生
面试官:那么你知道在哪里用这个内存屏障用得最多呢?单例模式
饿汉式、DCL懒汉式
饿汉式
DCL懒汉式
静态内部类
单例不安全, 因为反射
枚举
使用枚举,我们就可以防止反射破坏了。

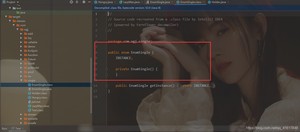
枚举类型使用JAD最终反编译后源码:
如果我们看idea 的文件:会发现idea骗了我们,居然告诉我们是有有参构造的,我们使用jad进行反编译。
什么是CAS?
大厂必须深入研究底层!!!!修内功!操作系统、计算机网络原理、组成原理、数据结构

Unsafe类
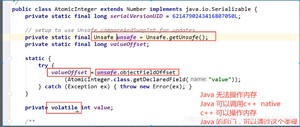
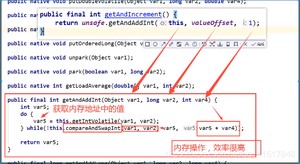
总结:
CAS:比较当前工作内存中的值 和 主内存中的值,如果这个值是期望的,那么则执行操作!如果不是就一直循环,使用的是自旋锁。
缺点:
- 循环会耗时;
- 一次性只能保证一个共享变量的原子性;
- 它会存在ABA问题
CAS:ABA问题?(狸猫换太子)
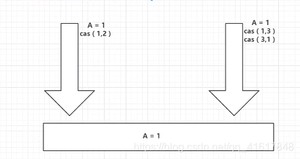
线程1:期望值是1,要变成2;
线程2:两个操作:
- 1、期望值是1,变成3
- 2、期望是3,变成1
所以对于线程1来说,A的值还是1,所以就出现了问题,骗过了线程1;
解决ABA问题,对应的思想:就是使用了乐观锁~
带版本号的 原子操作!
Integer 使用了对象缓存机制,默认范围是-128~127,推荐使用静态工厂方法valueOf获取对象实例,而不是new,因为valueOf使用缓存,而new一定会创建新的对象分配新的内存空间。

所以如果遇到,使用大于128的时候,使用原子引用的时候,如果超过了这个值,那么就不会进行版本上升!
那么如果我们使用小于128的时候:
正常业务操作中,我们一般使用的是一个个对象,一般情况不会遇到这种情况。
1、公平锁、非公平锁
公平锁:非常公平;不能插队的,必须先来后到;
非公平锁:非常不公平,允许插队的,可以改变顺序。
2、可重入锁
可重入锁(递归锁)
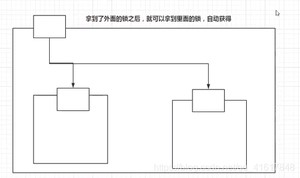
Synchronized锁
lock锁
- lock锁必须配对,相当于lock和 unlock 必须数量相同;
- 在外面加的锁,也可以在里面解锁;在里面加的锁,在外面也可以解锁;
3、自旋锁
spinlock
自我设计自旋锁:
运行结果:
t2进程必须等待t1进程Unlock后,才能Unlock,在这之前进行自旋等待。。。。

4、死锁
死锁是什么?
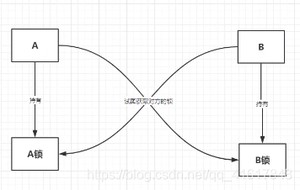
死锁测试,怎么排除死锁:
解决问题
1、使用jps定位进程号,jdk的bin目录下: 有一个jps
命令:
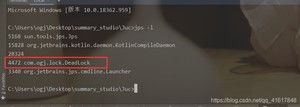
2、使用 进程进程号 找到死锁信息
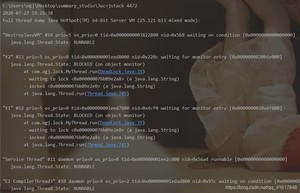
一般情况信息在最后:
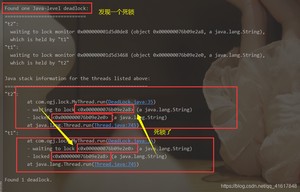
面试,工作中!排查问题!
1、日志
2、堆栈信息
}
}
运行结果:
t2进程必须等待t1进程Unlock后,才能Unlock,在这之前进行自旋等待。。。。
![[外链图片转存中...(img-G3eL8ITC-1595850751626)]](https://www.mushiming.com/uploads/202410/28/e8841f0f17e283c6.png)
4、死锁
死锁是什么?
死锁测试,怎么排除死锁:
解决问题
1、使用jps定位进程号,jdk的bin目录下: 有一个jps
命令:
![[外链图片转存中...(img-LeKLRYJj-1595850751627)]](https://www.mushiming.com/uploads/202410/28/c311f0e428bd94e5.png)
2、使用 进程进程号 找到死锁信息
![[外链图片转存中...(img-kQeUM5lC-1595850751627)]](https://www.mushiming.com/uploads/202410/28/8ebcea999e93d0bb.png)
一般情况信息在最后:
![[外链图片转存中...(img-DypkNFBU-1595850751627)]](https://www.mushiming.com/uploads/202410/28/5146e741d49f8afd.png)
面试,工作中!排查问题!
1、日志
2、堆栈信息
学习来自:JUC学习
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/4096.html