
LevelDB 是 C++ 开发的优秀的 LSM Tree 的存储组件,整体代码量不大,但是设计精巧,值得学习。在阅读源码过程中,整理了系列文章,逐步拆解 LevelDB 的实现细节。不过在阅读代码前,最好先准备好整个开发环境。
本文会从最基本的拉取代码开始,记录自己准备整个环境的过程,包括配置 VSCode IDE 和 clangd 插件使用,以及如何配置编译选项等。然后会通过简单的读写代码 demo,来简单使用下 LevelDB,对这个库有个感性的认识。另外,还会介绍如何运行测试用例,LevelDB 的测试用例写的很好,在代码阅读过程中,可以借助用例更好的理解代码。
首先是拉代码,这里使用的是 ,可以一次性拉取所有的子模块。虽然 leveldb 的实现不依赖第三方库,不过压测用到了 benchmark,功能测试用到了 googletest,这两个库都是作为子模块引入的。
如果拉取代码遇到网络问题,比如下面这种,需要先绕过防火墙才行,可以参考安全、快速、便宜访问 ChatGPT,最新最全实践教程! 这篇文章中的方法。
接下来就是编译整个源码,leveldb 用的 cmake 来构建,为了方便后面阅读代码,这里编译的时候加上了 ,这样会生成一个 文件,这个文件是 clangd 等工具的配置文件,可以帮助 VSCode 等 IDE 更好的理解代码。有了这个文件,代码跳转、自动补全等功能就会更好用。另外,为了方便用 GDB 进行调试,这里加上了 生成带调试信息的库。
完整的命令可以参考下面:
其中 选项用来指定安装目录,这里指定为当前目录(build 目录),这样编译完之后,生成的库文件和头文件都会放在 build 目录下,方便后续使用。
这里 CMake 构建有不少选项,比如 用来控制生成的库是静态链接库(.a 文件)还是动态链接库(.so 文件)。如果在 CMakeLists.txt 或通过命令行传递给 CMake 的参数中没有明确设置 ,CMake 的默认行为通常是不启用构建共享库。命令行可以用 来启用构建共享库。
个人平时用 vscode 比较多,vscode 作为代码 IDE,可以说是十分好用。对 C++ 项目来说,虽然微软提供了官方的 C++ 插件,方便代码跳转等,但从个人使用体验来说,并不好用。这里强烈推荐使用 clangd 来阅读 C++ 代码,只需要在服务器安装 Clangd,然后在 vscode 安装 clangd 插件,再配合前面 Cmake 生成的编译数据库文件 compile_commands.json 即可。
Clangd 是一个基于 LLVM 项目的语言服务器,主要支持 C 和 C++ 的代码分析。它可以提供代码补全、诊断(即错误和警告)、代码跳转和代码格式化等功能。和微软自带的 C++ 插件比,clangd 响应速度十分快,并且借助 clang 能实现更精准的跳转和告警等。还支持用 对项目代码进行静态分析,发现潜在错误。
比如在下面的代码中,clang-tidy 发现一个可疑问题:,还给出了 clang-tidy 的检查规则项 bugprone-sizeof-expression,这个规则是用来检查 表达式的使用是否正确。
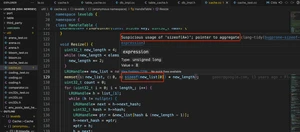
这里 new_list 本身是一个指向指针的指针,new_list[0] 实际上就是一个指针,sizeof(new_list[0]) 是获取指针的大小,而不是指针所指向的元素的大小。不过这里设计本意就是如此,就是要给新的 bucket 设置初始值 nullptr。其实这个规则想防止的是下面这种错误:
A common mistake is to compute the size of a pointer instead of its pointee. These cases may occur because of explicit cast or implicit conversion.
比如下面这类代码:
整体看,LevelDB 的代码质量很高,极少有 clang-tidy 提示。和业务代码的真是云泥之别,所以很值得学习。
LevelDB 并不是一个类似 mysql 这样的数据库,也不支持 SQL 查询等功能,它只是一个快速的 key-value 存储库。LevelDB 没有自带的客户端和服务器代码,如果需要提供存储功能,需要自己实现相应逻辑。此外,只支持单进程访问指定数据库,不支持多进程访问。
业界一般把 LevelDB 作为存储组件底层依赖的一个库来使用,比如微信的核心存储 paxosstore,就会用 LevelDB 来存储数据。LevelDB 的使用入门比较简单,只需要引入头文件,然后调用相应的接口即可。下面代码实现了一个简单的命令行接口,使用 LevelDB 库来读写 key。
这里用 Cmake 来构建,可以参考下面的 CMakeLists.txt 文件,当然下面的 include 和 lib 库的目录要根据前面编译好的目录来更改。
接着就可以用 来编译二进制文件了。当然不习惯 cmake,直接用 gcc 也是可以的,只是需要手动指定头文件和库文件的路径。然后执行如下图,可以在类似 redis 的命令行 client 中操作 LevelDB。
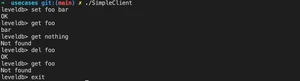
可以在当前目录的 db 文件夹,看到 LevelDB 的数据存储文件,如下:
后面会详细介绍 LevelDB 的数据存储方式,也会展开讲这些文件的作用,这里先不展开。
到现在为止,我们已经编译 LevelDB 库,并且用 LevelDB 写了一个简单的读写命令行接口。接下来看看 LevelDB 的测试用例。LevelDB 的核心代码都有配套的测试用例,比如 LRU cache 中的 cache_test.cc,db实现中的 db_test.cc,table 中的 table_test.cc 等等。用前面编译命令生成库的同时,会生成测试用例的可执行文件 。
如果直接运行 可能会提示缺少 动态库,这是 Google Perftools 的一个内存分配器,LevelDB 用到了这个库,需要在系统上安装。
安装命令也很简单,比如在 debian 系统上,可以使用下面的命令:
安装完之后,可以用 查看是否能找到,正常如下就可以运行二进制了。
这里在没有安装库之前,提示 ,安装动态库之后就自动链接到了正确的路径。怎么做到的呢?这是因为二进制文件包含了对动态库的引用,特别是库的名字和所需的符号(functions 或 data)。动态链接器(在 Linux 中通常是 )负责处理这些引用。它会确定二进制文件需要哪些库,然后按照指定的路径和方法加载用到的库。
我们安装 tcmalloc 库之后,动态库文件 libtcmalloc.so.4 被复制到系统的库目录 /usr/local/lib 中。然后安装程序会执行 ldconfig 更新 ld.so.cache,这个缓存包含库的路径信息,用来加快库的查找速度。这样后面再次运行二进制时,动态链接器查看缓存,找到新安装的库,并解析所有相关的符号引用,从而完成链接。
这些功能测试用例都是用 gtest 框架编写的,我们可以通过 参数查看所有的测试用例。如下图所示:
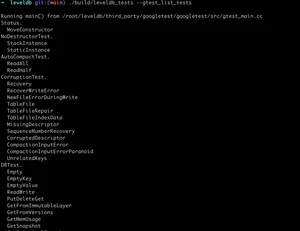
如果直接运行 leveldb_tests,会执行所有的测试用例,不过我们可以通过 参数来指定只运行某个测试用例,比如 只运行 LRU cache 相关的测试用例。结果如下:
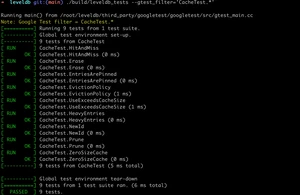
测试用例可以帮助更好的理解代码逻辑。在阅读代码的过程中,有时候想验证一些逻辑,因此可以改动一下测试用例。比如我把一个能通过的测试用例故意改坏:
修改用例后,需要重新编译 leveldb_tests。因为前面编译的时候,配置了项目的编译选项,CMake 已经缓存了下来,所以下面命令自动用了前面的配置项,比如 -DCMAKE_BUILD_TYPE=Debug 等。
注意上面的输出可以看到,这里只重新编译了改动的文件,生成了新的目标文件,因此编译速度很快。重新运行后,就会看到测试用例不过了,如下:
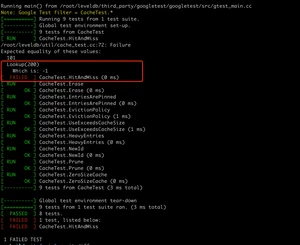
可以看到测试用例验证失败的具体原因。在阅读代码过程中,可以随时修改部分代码的用例,验证自己的理解是否正确。
跟着本文,大家应该都能快速准备好 LevelDB 的开发环境了吧。配置好 IDE,编译好源码,跑完简单的读写示例以及测试用例,然后一起来阅读源码吧~
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/4988.html