
HashMap 可以说是使用频率最高的处理键值映射的数据结构,它不保证插入顺序,允许插入 null 的键和值。本文采用 JDK8 中的源码,深入分析 HashMap 的原理、实现和优化。首发于微信公众号顿悟源码.
HashMap 基于散列表实现,使用拉链法处理碰撞,在 JDK8 中,当链表长度大于 8 时转为红黑树存储,基本结构如下:
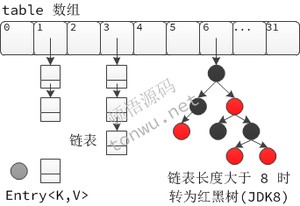
HashMap 有一个 Node<K,V>[] table 字段,即哈希桶数组,数组元素是 Node 对象,结构定义如下:
哈希桶数组会在首次使用时初始化,默认大小是 16,并根据需要调整大小,且长度总是 2 的次幂。如果构造函数设置的初始容量不是 2 的次幂,那么使用以下方法返回一个大于且最靠近它的 2 的次幂的值:
原理就是将最高位 1 右边的所有比特位全置为 1,然后再加 1,最高位进 1,右边的比特位全变成 0,从而得出一个 2 的次幂的值。在 JDK7 中使用的是 Integer.highestOneBit(int i) 方法,它最后计算时使用 n - (n >>> 1) 返回的是一个小于且最靠近入参的 2 的次幂。
HashMap 内部的其他字段:
影响 HashMap 性能的主要参数是:初始容量和负载因子。当散列表元素数超过负载因子和当前容量的乘积时,就会扩容,扩大到原来容量的两倍,并对键重新散列。
- 初始容量过小会多次触发扩容和 rehash,所以预分配一个足够大的容量更加有效
- 负载因子默认值是 0.75f,它是对时间和空间成本的一个很好的平衡,一般不用修改,较高的值会减少空间开销,但会增加查找的成本
不管多么合理的散列算法,也免不了链表过长的情况,从而影响 HashMap 的性能,所以,JDK8 在链表长度大于 8 时,将其转为红黑树,以利用红黑树快速增删改查的特点。
将整数散列最常用的方法就是除留余数法。为了均匀地散列键的散列值,通常都会把数组的大小取素数(HashTable 的初始大小就是 11),因为素数的因子少,余数相等的概率小,冲突的几率就小。
HashMap 的容量始终是 2 的次幂,这是一个合数,之所以这样设计,是为了将取模运算转为位运算,提高性能。这个等式成立的原因如下:
右边是 2^n 的二进制特点,左边是 2^n-1 的特点,可以发现当 length = 2^n 时,h & (length-1) 的结果正好位于 0 到 length-1 之间,就相当于取模运算。
转为位运算后,length-1 就相当于一个低位掩码,在按位与时,它会把原散列值的高位置0,这就导致散列值只在掩码的小范围内变化,显然增大了冲突几率。为了减少冲突,HashMap 在设计散列算法时,使用高低位异或,变相的让键的高位也参与了运算,代码如下:
高位的移位异或,既能保证有效的利用键的高低位信息,又能减少系统开销,这样设计是对速度、效率和质量之间的权衡。
put 操作主要做了以下几件事:
- 哈希桶数组 table 为空时,通过 resize() 方法进行初始化
- 待插入的 key 已存在,直接覆盖 value
- 若不存在,将键值对插入到对应的链表或红黑树中
- 插入链表时判断是否转红黑树
- 判断是否需要扩容
核心代码如下:
JDK8 在插入链表时采用的是尾插入法,也就是顺序插入,而 JDK7 使用的是头插法,逆序插入。
默认情况下,初始容量是 16,负载因子是 0.75f,threshold 是 12,也就是说,插入 12 个键值对就会扩容。
在扩容时,会扩大到原来的两倍,因为使用的是2的次幂扩展,那么元素的位置要么保持不变,要么在原位置上偏移2的次幂。
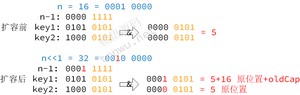
上图可以看到,扩大2倍,相当于 n 左移一位,那么 n-1 在高位就多出了一个 1,此时与原散列值进行与运算,就多参与了一位,这个比特位要么是 0,要么是 1:
- 0 的话索引不变
- 1 的话索引就变成"原索引+oldCap"
那么怎么判断这个比特位是0还是1呢?如果"原散列值 & oldCap"的值为0,则表示比特位是0。扩容代码如下:
在重新计算链表中元素位置时,只可能得到两个子链表:索引不变的元素链表和有相同偏移量的元素链表。在构造子链表的过程中,使用头节点和尾节点,保证了拆分后的有序性:
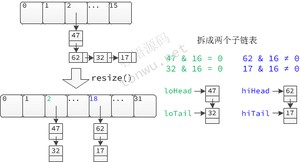
查看 TreeNode.split() 方法发现,红黑树拆分的逻辑和链表一样,只不过在拆分完成后,会根据子链表的长度做以下处理:
- 长度小于 6,返回一个不包含 TreeNode 的普通链表
- 否则,把子链表转为红黑树
红黑树之所以能够按照链表的逻辑拆分,是因为链表在转红黑树时,保留了原链表的链条引用,这样也方便了遍历操作。
链表转红黑树主要做了以下几件事:
- 判断桶容量是否达到树化的最低要求,否则进行扩容
- 将原链表转为由 TreeNode 组成的双向链表
- 将新链表转为红黑树
代码如下:
HashMap 在设计时应该没有考虑后期会引入红黑树,所以没有提供 key 的比较器或要求 key 实现 Comparable 接口。为了比较两个 key 的大小,HashMap 按以下步骤处理:
- 如果两个 key 的 hash 值不等,则比较 hash 值大小
- 如果相等,若 key 实现了 Comparable 接口,使用 compareTo 方法比较
- 如果结果还是相等,使用自定义的 tieBreakOrder 方法比较,逻辑如下
JDK8 中的 HashMap 代码还是比较复杂的,优化方面主要有以下三点:
- 优化 hash 算法只进行一次位移操作
- 引入红黑树,在冲突比较严重的情况下,将 get 操作的时间复杂从 O(n) 降为了 O(logn)
- 扩容时,利用 2 的次幂数值的二进制特点,既省去重新计算 hash 的时间,又把之前冲突的节点散列到了其他位置
此外,HashMap 是非线程安全的,线程间的竞争条件主要是发生冲突或扩容时,链表的断链和续链操作。扩容也就意味着内存拷贝,这是一个很耗费性能的操作,所以预分配一个足够大的初始容量,减少扩容的次数,能够让 HashMap 有更好的表现。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/5005.html