
原文:https://blog.csdn.net/orecle_littleboy/article/details/
ORM(Object Relational Mapping,对象关系映射)模式是一种为了解决面向对象与关系数据库存在的互不匹配的技术。简单的说,ORM是通过描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
到底如何实现持久化呢?一种简单的方案是采用硬编码方式,为每一种可能的数据库访问操作提供单独的方法。
硬编码方式方案存在以下不足:
1.持久化层缺乏弹性。一旦出现业务需求的变更,就必须修改持久化层的接口
2.持久化层同时与域模型与关系数据库模型绑定,不管域模型还是关系数据库模型发生变化,都要修改持久化层的代码,增加了软件的维护难度。
ORM提供了实现持久化层的另一种模式,它采用映射元数据来描述对象关系的映射,使得ORM中间件能在任何一个应用的业务逻辑层和数据库层之间充当桥梁。
Java典型的ORM中间件有:Hibernate , ibatis , speedframework。
ORM的方法论基于三个核心原则:
· 简单:以最基本的形式建模数据。
· 传达性:数据库结构被任何人都能理解的语言文档化。
· 精确性:基于数据模型创建正确标准化了的结构。
让我们从O/R开始。字母O起源于"对象"(Object),而R则来自于"关系"(Relational)。几乎所有的程序里面,都存在对象和关系数据库。在业务逻辑层和用户界面层中,我们是面向对象的。当对象信息发生变化的时候,我们需要把对象的信息保存在关系数据库中。
当你开发一个应用程序的时候(不使用O/R Mapping),你可能会写不少数据访问层的代码,用来从数据库保存,删除,读取对象信息,等等。你在DAL(数据访问层)中写了很多的方法来读取对象数据,改变对象状态等等任务。而这些代码重复性强。
ORM解决的主要问题是对象关系的映射。域模型和关系模型分别是建立在概念模型的基础上的。域模型是面向对象的,而关系模型是面向关系的。一般情况下,一个持久化类和一个表对应,类的每个实例对应表中的一条记录,类的每个属性对应表的每个字段。
ORM技术特点:
1.提高了开发效率。由于ORM可以自动对Entity对象与数据库中的Table进行字段与属性的映射,所以我们实际可能已经不需要一个专用的、庞大的数据访问层。
2.ORM提供了对数据库的映射,不用sql直接编码,能够像操作对象一样从数据库获取数据。
A . 简单:ORM以最基本的形式建模数据。比如ORM会将的一张表映射成一个类(模型),表的字段就是这个类的成员变量
B . 精确:ORM使所有的MySQL数据表都按照统一的标准精确地映射成java类,使系统在代码层面保持准确统一
C .易懂:ORM使数据库结构文档化。比如MySQL数据库就被ORM转换为了java程序员可以读懂的java类,java程序员可以只把注意力放在他擅长的java层面(当然能够熟练掌握MySQL更好)
D.易用:ORM包含对持久类对象进行CRUD操作的API,例如create(), update(), save(), load(), find(), find_all(), where()等,也就是讲sql查询全部封装成了编程语言中的函数,通过函数的链式组合生成最终的SQL语句。通过这种封装避免了不规范、冗余、风格不统一的SQL语句,可以避免很多人为Bug,方便编码风格的统一和后期维护。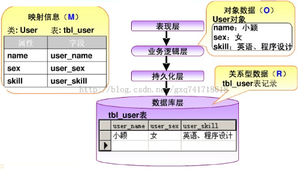
ORM的缺点是会牺牲程序的执行效率和会固定思维模式。
从系统结构上来看,采用ORM的系统一般都是多层系统,系统的层次多了,效率就会降低。ORM是一种完全的面向对象的做法,而面向对象的做法也会对性能产生一定的影响。
- ORM所生成的代码一般不太可能写出很高效的算法,如用了ORM,程序员很有可能将全部数据提取到内存对象中,然后再进行过滤和处理,这样就容易产生性能问题。
- 对象持久化时,ORM一般会持久化对象的所有属性,有时这是不希望的。
- ORM是一种工具,能解决一些重复简单的劳动,但不能指望能一劳永逸的解决所有问题,有些问题还是需要特殊处理,对绝大多数的系统而言需要特殊处理的部分很少。
什么是ORM为什么要使用ORM?
什么是“持久化”(Persistence):
即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的数据存储在关系型的数据库中,当然也可以存储在磁盘文件中、XML数据文件中等等。
另一种描述:数据持久化(PO)就是将内存中的数据模型转换为存储模型,以及将存储模型转换为内存中的数据模型的统称.数据模型可以是任何数据结构或对象模型,存储模型可以是关系模型、XML、二进制流等。cmp和Hibernate只是对象模型到关系模型之间转换的不同实现。
什么是“持久层”(Persistence Layer):
即专注于实现数据持久化应用领域的某个特定系统的一个逻辑层面,将数据使用者和数据实体相关联。
什么是ORM :
在关系型数据库和对象之间作一个映射,在操作数据库时不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了 。
为什么要做持久化和ORM设计
在目前的企业应用系统设计中,MVC,即 Model(模型)- View(视图)- Control(控制)为主要的系统架构模式。MVC 中的 Model 包含了复杂的业务逻辑和数据逻辑,以及数据存取机制(如 JDBC的连接、SQL生成和Statement创建、还有ResultSet结果集的读取等)等。将这些复杂的业务逻辑和数据逻辑分离,以将系统的紧耦合关系转化为松耦合关系(即解耦合),是降低系统耦合度迫切要做的,也是持久化要做的工作。MVC 模式实现了将表现层(即View)和数据处理层(即Model)分离的解耦合,而持久化的设计则实现了数据处理层内部的业务逻辑和数据逻辑分离的解耦合。而 ORM 作为持久化设计中的最重要也最复杂的技术,也是目前业界热点技术。
简单来说,按通常的系统设计,使用 JDBC 操作数据库,业务处理逻辑和数据存取逻辑是混杂在一起的。
一般基本都是如下几个步骤:
1、建立数据库连接,获得 Connection 对象。
2、根据用户的输入组装查询 SQL 语句。
3、根据 SQL 语句建立 Statement 对象 或者 PreparedStatement 对象。
4、用 Connection 对象执行 SQL语句,获得结果集 ResultSet 对象。
5、然后一条一条读取结果集 ResultSet 对象中的数据。
6、根据读取到的数据,按特定的业务逻辑进行计算。
7、根据计算得到的结果再组装更新 SQL 语句。
8、再使用 Connection 对象执行更新 SQL 语句,以更新数据库中的数据。
7、最后依次关闭各个 Statement 对象和 Connection 对象。
可见代码逻辑比较复杂,这还不包括语句执行失败的处理逻辑。业务处理逻辑和数据存取逻辑混杂在一起。另一方面,假如要换数据库产品或者运行环境也可能是个不可能完成的任务。而用户的运行环境和要求却千差万别,我们不可能为每一个用户每一种运行环境设计一套一样的系统。
所以就要将一样的业务处理逻辑和不一样的数据存取逻辑分离开来,另一方面,关系型数据库中的数据基本都是以一行行的数据进行存取的,而程序运行却是一个个对象进行处理,而目前大部分数据库驱动技术(如ADO.NET、JDBC、ODBC等等)均是以行集的结果集一条条进行处理的。所以为解决这一困难,就出现 ORM 这个对象和数据之间映射技术。
举例来说,比如要完成一个购物打折促销的程序,用 ORM 思想将如下实现(引自《深入浅出Hibernate》):
业务逻辑如下:
public Double calcAmount(String customerid, double amount)
{
// 根据客户ID获得客户记录
Customer customer = CustomerManager.getCustomer(custmerid);
// 根据客户等级获得打折规则
Promotion promotion = PromotionManager.getPromotion(customer.getLevel());
// 累积客户总消费额,并保存累计结果
customer.setSumAmount(customer.getSumAmount().add(amount);
CustomerManager.save(customer);
// 返回打折后的金额
return amount.multiply(protomtion.getRatio());
}
这样代码就非常清晰了,而且与数据存取逻辑完全分离。设计业务逻辑代码时完全不需要考虑数据库JDBC的那些千篇一律的操作,而将它交给 CustomerManager 和 PromotionManager 两个类去完成。这就是一个简单的 ORM 设计,实际的 ORM 实现框架比这个要复杂的多。
(1)Hibernate 全自动 需要写HQL语句
(2)iBATIS 半自动 自己写sql语句,可操作性强,小巧
(3)mybatis
(4)eclipseLink
(5)JFinal
注:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/5212.html