
传送门:点我。
大家好,这里是 Codeman 。这是本文的第二次修订,在前文的基础之上,这次我增加了很多公式的推导,从数学原理到代码实现,本文提供了一站式服务,希望能帮助读者从根上理解逻辑回归,一劳永逸地解决问题!
多次修订,只源于我精益求精的人生态度。写博客,我是认真的!如果你觉得本文确实对你有帮助,请点个赞支持我一下吧 🌹
逻辑回归在社会和自然科学中应用非常广泛,它其实是一种统计学习方法,因为它的底层方法就是线性回归。它们不同的地方在于:线性回归适用于解决回归问题,而逻辑回归适用于解决分类问题。这是为什么呢?别急,看完本文你就懂了。因此,我们可以说逻辑回归是基于回归的伪回归算法!

在自然语言处理中,逻辑回归是用于分类的基线监督机器学习算法,它与神经网络也有非常密切的关系,神经网络可以被视为一系列堆叠在一起的逻辑回归分类器。
由于后文涉及到很多数学公式的推导,因此我们先做一个符号约定:
我们先从线性回归开始讲起,一步一步地领略逻辑回归的全貌。
线性回归是一种使用特征属性的线性组合来预测响应的方法。它的目标是找到一个线性函数,以尽可能准确地描述特征或自变量()与响应值()之间的关系,使得预测值与真实值之间的误差最小化。
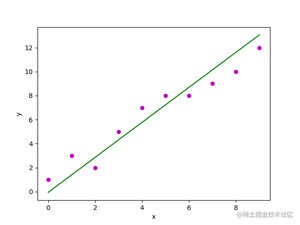
在数学上,线性回归要找的这个线性函数叫回归方程,其定义如下:
其中,表示第 个样本的预测响应值。 和 是回归系数,分别代表回归线的 轴截距和斜率。这种形式通常见于特征只有单个属性的时候,也就是一元线性回归,我们初高中所学的就是这种。
在机器学习中,通常每个样本都有 个特征属性,每个特征 都有一个对应的权值 ,此时我们需要的就是多元线性回归:
其中, 没有实义,只是为了方便写成矩阵的形式, 则等价于式 (1.1) 中的 ,把 融入矩阵中,不仅为了看起来简洁,也是为了方便计算。
若损失函数采用平方和损失:
则代价函数定义如下:
损失函数(Loss Function)度量单样本预测的误差,代价函数(Cost Function)度量全部样本的平均误差。常用的代价函数有均方误差、均方根误差、平均绝对误差等。
损失函数的系数 1/2 是为了便于计算,使对平方项求导后的常数系数为 1。
我们的目标是要找到一组 ,使得代价函数 最小,即最小化 。
下面我们将详细描述用最小二乘法求 的推导过程。
为了方便叙述,我们将用矩阵形式表达,即:
其中, 为 行 列的矩阵(第一列全为 ,即式 (1.2) 中的 ), 为 行 列的矩阵(包含了 ), 为 行 列的矩阵。
对式 (1.5) 求导,可得:
又 ,,所以
令,则:
由上式可知,最小二乘法需要计算,但是矩阵求逆的时间复杂度为 ,因此当特征数量 较大时,其运算代价非常大。所以这种方法只适用于特征数量较少的线性模型,不适用于其他模型。
现代机器学习中常用的参数更新方法是梯度下降法。
根据梯度下降的每一步中用到的样本数量,可以将梯度下降法分为以下三类:
其中, 称为学习率。根据公式,不难看出,BGD 和 SGD 其实是 MBGD 的 取值为 和 时的特殊情况。我们以 SGD 为例,推导一遍参数的更新过程。
又 ,所以
监督学习主要分回归和分类两种,二者的评价指标是截然不同的。我们先在此介绍回归的评价指标。
首先是误差要越小越好,主要是下面几种:
其次是 要越大越好,它越接近于 1,说明模型拟合得越好。计算公式如下:
其中,,,。
SST 是 Sum of Squares Total 的缩写,含义是总平方和。它是变量 与其平均值 之差的平方和。我们可以将其视为对于变量 在其平均值 周围的分散程度的一种度量,很像描述性统计中的方差。
SSR 是 Sum of Squares Regression 的缩写,含义是回归的平方和。它是预测值 与平均值 之差的平方和。我们可以将其视为描述回归线与数据的拟合程度的一种度量。
SSE 是 Sum of Squares Error 的缩写,含义是误差的平方和。它是预测值 与观测值 之差的平方和。
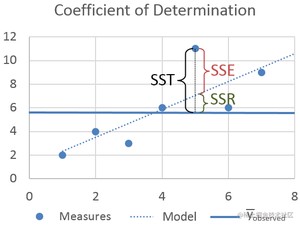
从图中不难看出,三者的关系是:SST = SSR + SSE。如果 SSR 的值等于 SST,这意味着我们的回归模型是完美的。
我们前面说过,逻辑回归和线性回归不同的地方在于:线性回归适用于解决回归问题,而逻辑回归适用于解决分类问题。本节我们就讲讲造成这种差异的原因。
我们知道逻辑回归的目标是训练一个分类器,该分类器可以对输入数据的类别做出决策。以二元逻辑回归为例,对于一个输入 ,我们希望分类器能够输出 是 1(是某类的成员)或 0(不是某类的成员)。也就是说,我们想知道这个输入 是该类成员的概率 。
我们知道逻辑回归的底层就是线性回归,但是线性回归解决的是回归问题,那我们如何将一个回归问题转化为一个分类问题呢?为了方便讨论,我们再对式 (1.2) 做一点形式变换,即令
有些地方写的是 ,其实是一样的,因为 可以融入到 中。
我们观察式 (2.1),不难发现, 的输出范围没有任何限制,即 。而作为一个分类器,我们需要输出的是位于 0 和 1 之间的合法概率值。而为了完成这一步转变,我们就需要 Sigmoid函数 。Sigmoid 函数(命名是因为它的图像呈𝑆形)也称为逻辑函数,逻辑回归的名称也由此而来。
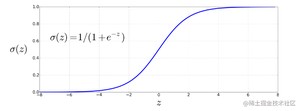
Sigmoid 有许多优点,它能将任意实数映射到 范围内,而且任意阶可导。它在 0 附近几乎是线性的,但在两端趋于平缓,它能将异常值压向 0 或 1。
我们将式 (2.1) 的值代入上式,就能得到一个介于 0 和 1 之间的概率。对于一个二元逻辑回归,我们只需要确保 即可。我们可以这样做:
根据 Sigmoid 函数的性质:
我们也可以将 表示为 。
好了,现在我们已经有了概率值,那么概率值大于多少我们认为它是属于 1 类呢?通常,如果概率 大于 ,我们认为是,否则就不是。这个 0.5 被称为决策边界。
总结:逻辑回归的总体思路就是,先用逻辑函数把线性回归的结果 (-∞,∞) 映射到 (0,1),再通过决策边界建立与分类的概率联系。
逻辑函数还有一个很好的特性就是,其导函数可以转化成本身的一个表达式,推导过程如下:
在二分类模型中,事件发生与不发生的概率之比 称为事件的几率(odds)。令,解得:
也就是说,线性回归的结果(即 )等于对数几率。
下面我们讲讲模型的参数如何更新。我们使用极大似然估计法来求解。极大似然估计法利用已知样本结果,反推最有可能导致这样结果的原因。我们的目标就是找到一组参数,使得在这组参数下,我们的样本的似然度(概率)最大。
对于一个二分类模型,已知 , 则似然函数为:
等式两边同时取对数:
则代价函数为:
其实,式(2.9)前面再加一个负号,就是我们常用的损失函数——交叉熵损失(cross-entropy loss)。
代价函数之所以要加负号,是因为机器学习的目标是最小化损失函数,而极大似然估计法的目标是最大化似然函数。那么加个负号,正好使二者等价。
求解逻辑回归的方法有非常多,我们这里主要了解一下梯度下降法。
将式 (2.2) 代入式 (2.10),得:
对 求偏导,得:
所以:
逻辑回归对特征变量(x)和分类响应变量(y)之间的关系进行建模,在给定一组预测变量的情况下,它能给出落入特定类别响应水平的概率。也就是说,你给它一组数据(特征),它告诉你这组数据属于某一类别的概率。根据分类响应变量(y)的性质,我们可以将逻辑回归分为三类:
- 二元逻辑回归(Binary Logistic Regression)
当分类结果只有两种可能的时候,我们就称为二元逻辑回归。例如,考试通过或未通过,回答是或否,血压高或低。 - 名义逻辑回归(Nominal Logistic Regression)
当存在三个或更多类别且类别之间没有自然排序时,我们就称为名义逻辑回归。例如,企业的部门有策划、销售、人力资源等,颜色有黑色、红色、蓝色、橙色等。 - 序数逻辑回归(Ordinal Logistic Regression)
当存在三个或更多类别且类别之间有自然排序时,我们就称为序数逻辑回归。例如,评价有好、中、差,身材有偏胖、中等、偏瘦。注意,类别的排名不一定意味着它们之间的间隔相等。
我们以上讨论都是以二元分类为前提展开的,但有时可能有两个以上的类,例如情绪分类有正面、负面或中性三种,手写数字识别有 0-9 总共十种分类。
在这种情况下,我们需要多元逻辑回归,也称为 Softmax Regression。在多元逻辑回归中,我们假设总共有 个类,每个输入 只能属于一个类。也就是说,每个输入 的输出 将是一个长度为 的向量。如果类 是正确的类,则设置,其他元素设置为 0,即。这种编码方式称为 one-hot 编码。此时,分类器的工作是产生一个估计向量。对于每个类 ,产生一个概率估计 。
多元逻辑分类器采用 sigmoid 的泛化函数 softmax 来计算 。它能将 个任意值的向量 映射到 (0,1) 范围内的概率分布上,并且所有值的总和为 1 。其定义如下:
因此,输入向量 的 softmax输出如下:
举个例子,若 ,则
与 sigmoid 一样,softmax 也具有将异常值压向 0 或 1 的特性。因此,如果其中一个输入远大于其他输入,它将倾向于将其概率推向 1,并抑制较小输入的概率。
由于现在有 个类别,而且每一个类别都有一个单独的权重向量 ,则每个输出类别的概率估计 应该这样计算:
上式看起来我们将分别每个类别计算输出。但是,我们可以将 个权重向量表示为权重矩阵 。 的第 列对应于权重向量 。因此, 的形状为 ,其中, 是输出类的数量, 是输入特征的数量,加 对应的就是偏置。这样一来,我们还是可以通过一个优雅的公式计算 :
在 Pytorch 中可以通过继承类来实现自定义模型,在中定义每一层的构造,在中定义每一层的连接关系,是实现模型功能的核心,且必须重写,否则模型将由于无法找到各层的连接关系而无法执行。
对传入的数据做线性变换, 和 是它的两个变量,分别代表学习的权值和偏置。
我们以鸢尾花数据的分类为例,做一个简单地用 Logistic 回归进行分类的任务。
- 数据集获取与划分
实际的数据共有152行,我们只取前100行。按照下标随机打乱之后来划分训练集和测试集。其中,训练集有75行,测试集有25行。

- 模型训练
计算目标值和预测值之间的二进制交叉熵损失函数,数学公式如下:
其中,、、 分别表示权值、标签(target)、预测概率值(input probabilities)。取值为表明对样本的损失值进行求和。
输出如下:
- 模型评估
输出如下:
Test set accuracy: 100.00%
一个非常基础的入门级的机器学习算法,但是要完全讲透还是非常困难,尤其是公式的推导部分,光用文字描述很难讲清楚,但是总体上公式的推导都没问题,只是说第一眼看不是那么容易懂,多看几遍或者自己在纸上写一写还是不难理解的。另外,也请读者发现错误后能在评论区指出,我看到后会及时更正。
全文写下来洋洋洒洒六千字,也花费了好几天的时间,从自己理解到写出来让别人看懂,这之间差别真的很大,可能也是我不善于表达,词不达意,也请大家见谅。
篇幅这么长,公式这么多,看完本文你可能什么也记不住,但是这两点你一定要记住:
1. Logistic回归不适用于解决回归问题,它适用于解决分类问题。千万不要被它的名称迷惑!
2. Logistic回归 = 线性回归 + Sigmoid 函数。当然了,如果是多元回归的话就是 softmax 函数。
例行公事😂:如果你觉得本文确实对你有帮助,请点个赞支持我一下吧 🌹
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/6065.html