
最近使用STM32F103+W25Q64+USB+FATFS做了一个U盘设备。程序已经调试完成了,现在重新梳理一下知识再做一个记录。
STM32F103+USB是根据官方demo修改的。USB大容量存储器的移植在下一篇文章介绍。本篇文章主要介绍W25Q64和驱动函数。
W25Q64容量是64Mbit的flash,64Mbit = 8MByte。
其内部组织关系如下:
W25Q64内部分为128个块(Block),每个块的大小是64K字节。 计算方式: (81024)K/128 = 64K字节。
每个块分为16个扇区(Sector),每个扇区的大小是4K字节。计算方式:64K/16 = 4K字节。
每个扇区分为16页(Page),每个页的大小是256个字节。计算方式:(41024)Byte/16 = 256Byte。
W25Q64和STM32的接线方式如下
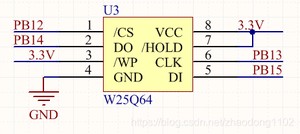
PB12是SPI的片选接W25Q64的片选,程序中的片选是使用通用IO控制的。
PB13是SPI的时钟输出接W25Q64的时钟。
PB14是SPI的主机输入从机输出,接W25Q64的DO。
PB15是SPI的主机输出从机输入,接W25Q64的DI。
STM32的SPI初始化。
此函数是后续一切函数的基础。我们先来看一下W25Q64的命令相关的函数。
以上是一些最常用的指令函数,如果需要其它命令的函数,照葫芦画瓢就行。
然后我们介绍最重要的三个函数、和
函数功能:从开始的地址读取个数据到指向的起始地址处。
我们看一下读取指令的特点

意思就是说发送完读取指令以后,只要不断的读可以把整个芯片的数据都读取出来,不受页,扇区,块等分区的限制。因此函数就很简洁。
函数的功能:把从地址开始的数据写入到开始的地址处,写入个,使用该函数一定要保证待写入的flash空间是擦除过的。
写函数咋这么复杂呢?为啥不能用与读取数据相同的套路呢?

我记得EEPROM也有这个特点,是叫做“页卷”。写完一页必须重新发送地址,否则地址自动变为页的开始地址,后边写入的数据会覆盖前边写入的数据,EEPROM会覆盖,SPI FLASH不会,为什么呢?因为FLASH写入之前需要擦除。
由于上边的缘故我们的写函数逻辑上就稍微复杂了。一定要记住flash写入之前必须擦除(以保证flash待写区域是0XFF),写flash内部的数据只能由1变为0不能由0变为1,想由0变为1必须擦除,擦除以后flash内部的数据就是0xFF了。所以调用函数之前要保证flash的待写区域是0xFF。
flash一次最多写入256个字节。顺带说一下擦除一次最少擦除4K字节(最小的擦除单位是一个Sector)。W25Q64可没有“页擦除”
下面再介绍一个写入函数,该写入函数的好处是调用函数的时候不用考虑flash是否需要擦除,函数内部处理了这个擦操作。直接指定flash空间地址,缓存地址,写入个数就可以了,一句话总结就是省心。
函数的功能:把从地址开始的数据写入到开始的地址处,写入个
貌似这个函数用起来很省心,但是我们在享受省心的同时却带来了性能下降的问题(这就像世界上没有一份工作是钱多事少离家近的)。
假设如下情景:
当我们每次只写入一个字节数据,写4K字节空间的话,函数内部需要4096次读,擦,写。需要先把数据从flash搬运到内存,擦除flash,然后再写入。使用函数只要写就可以了,函数内部不会读取和擦除。擦除巨耗时,所以性能急剧下降。
函数用在性能要求不高的场合还是可以的。如果用在SPI FLASH模拟U盘这种场景下,性能不忍直视,速度感人。
到此STM32驱动SPI FLASH就介绍完了,下一篇我们介绍 SPI FLASH如何模拟U盘以及如何提升性能。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/6670.html