
作为后端开发,我们经常需要设计数据库表。整理了 21 个设计 MySQL 表的经验准则,分享给大家,大家看完一定会有帮助的。
数据库表名、字段名、索引名等都需要命名规范,可读性高(一般要求用英文),让别人一看命名,就知道这个字段表示什么意思。
比如一个表的账号字段,反例如下:
正例:
设计表时,我们需要选择合适的字段类型,比如:
主键设计的话,最好不要与业务逻辑有所关联。有些业务上的字段,比如身份证,虽然是唯一的,一些开发者喜欢用它来做主键,但是不是很建议哈。主键最好是毫无意义的一串独立不重复的数字,比如,又或者自增的主键,或者是雪花算法生成的主键等等;
先问大家一个问题,大家知道数据库字段长度表示字符长度还是字节长度嘛?
其实在 mysql 中,和类型表示字符长度,而其他类型表示的长度都表示字节长度。比如表示字符长度是 10,而表示显示长度是个字节,但是因为 bigint 实际长度是个字节,所以 bigint(4)的实际长度就是 8 个字节。
我们在设计表的时候,需要充分考虑一个字段的长度,比如一个用户名字段(它的长度 5~20 个字符),你觉得应该设置多长呢?可以考虑设置为 。字段长度一般设置为 2 的幂哈(也就是次方)。
什么是物理删除?什么是逻辑删除?
物理删除就是执行语句,如删除的账户信息 SQL 如下:
逻辑删除呢,就是这样:
为什么推荐用逻辑删除,不推荐物理删除呢?
表必备一般来说,或具备这几个字段:
我们建表的时候,要牢记,一张表的字段不宜过多哈,一般尽量不要超过 20 个字段哈。笔者记得上个公司,有伙伴设计开户表,加了五十多个字段。。。
如果一张表的字段过多,表中保存的数据可能就会很大,查询效率就会很低。因此,一张表不要设计太多字段哈,如果业务需求,实在需要很多字段,可以把一张大的表,拆成多张小的表,它们的主键相同即可。
当表的字段数非常多时,可以将表分成两张表,一张作为条件查询表,一张作为详细内容表 (主要是为了性能考虑)。
如果没有特殊的理由, 一般都建议将字段定义为 。
为什么呢?
首先,评估你的表数据量。如果你的表数据量只有一百几十行,就没有必要加索引。否则设计表的时候,如果有查询条件的字段,一般就需要建立索引。但是索引也不能滥用:
假设你新建一张用户表,如下:
对于这张表,很可能会有根据或者查询用户信息,并且,是唯一的。因此,你是可以给加上唯一索引,加上普通索引。
什么是数据库三范式(),大家是否还有印象吗?
我们设计表及其字段之间的关系, 应尽量满足第三范式。但是有时候,可以适当冗余,来提高效率。比如以下这张表
以上这张存放商品信息的基本表。这个字段的存在,表明该表的设计不满足第三范式,因为可以由得到,说明是冗余字段。但是,增加这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。
当然,这只是个小例子哈,大家开发设计的时候,要结合具体业务分析哈。
如果库名、表名、字段名等属性含有保留字时,语句必须用反引号来引用属性名称,这将使得 SQL 语句书写、SHELL 脚本中变量的转义等变得非常复杂。
因此,我们一般避免使用保留字,如等等
什么是外键呢?
外键,也叫,它是用于将两个表连接在一起的键。是一个表中的一个字段(或字段集合),它引用另一个表中的。它是用来保证数据的一致性和完整性的。
阿里的规范也有这么一条:
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
我们为什么不推荐使用外键呢?
建表是需要选择存储引擎的,我们一般都选择存储引擎,除非读写比率小于, 才考虑使用。
有些小伙伴可能会有疑惑,不是还有等其他存储引擎吗?什么时候使用它呢?其实其他存储引擎一般除了都建议在的指导下使用。
我们来复习一下这这三种存储引擎的对比区别吧:
数据库库、表、开发程序等都需要统一字符集,通常中英文环境用。
MySQL 支持的字符集有等。
如果你设计的数据库字段是枚举类型的话,就需要在后面注释清楚每个枚举的意思,以便于维护
正例如下:
反例:
并且,如果你的枚举类型在未来的版本有增加修改的话,也需要同时维护到后面。
我们设计表的时候,一般都需要加通用时间的字段,如等等。那对于时间的类型,我们该如何选择呢?
对于 MySQL 来说,主要有。
推荐优先使用类型来保存日期和时间,因为存储范围更大,且跟时区无关。
什么是存储过程
已预编译为一个可执行过程的一个或多个 SQL 语句。
什么是触发器
触发器,指一段代码,当触发某个事件时,自动执行这些代码。使用场景:
对于 MYSQL 来说,存储过程、触发器等还不是很成熟, 并没有完善的出错记录处理,不建议使用。
日常开发中,对多的关系应该是非常常见的。比如一个班级有多个学生,一个部门有多个员工等等。这种的建表原则就是:在从表(的这一方)创建一个字段,以字段作为外键指向主表(的这一方)的主键。示意图如下:
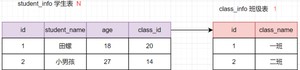
学生表是多()的一方,会有个字段保存班级表的主键。当然,一班不加外键约束哈,只是单纯保存这个关系而已。
有时候两张表存在关系时,我们应该消除这种关系。通过增加第三张表,把修改为两个 。比如图书和读者,是一个典型的多对多的关系。一本书可以被多个读者借,一个读者又可以借多本书。我们就可以设计一个借书表,包含图书表的主键,以及读者的主键,以及借还标记等字段。
设计表的时候,我们尤其需要关注一些大字段,即占用较多存储空间的字段。比如用来记录用户评论的字段,又或者记录博客内容的字段,又或者保存合同数据的字段。如果直接把表字段设计成 text 类型的话,就会浪费存储空间,查询效率也不好。
在 MySQl 中,这种方式保存的设计方案,其实是不太合理的。这种非常大的数据,可以保存到中,然后,在业务表保存对应的即可。
这种设计思想类似于,我们表字段保存图片时,为什么不是保存图片内容,而是直接保存图片 url 即可。
什么是分库分表呢?
分库就是一个数据库分成多个数据库,部署到不同机器。
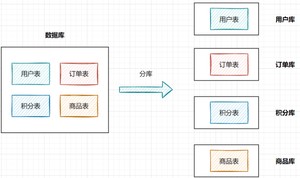
分表就是一个数据库表分成多个表。
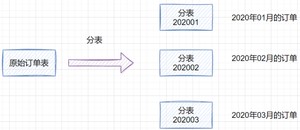
我们在设计表的时候,其实可以提前估算一下,是否需要做分库分表。比如一些用户信息,未来可能数据量到达百万设置千万的话,就可以提前考虑分库分表。
为什么需要分库分表: 数据量太大的话,SQL 的查询就会变慢。如果一个查询 SQL 没命中索引,千百万数据量级别的表可能会拖垮整个数据库。即使 SQL 命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是 B+树结构,数据千万级别的话,B+树的高度会增高,查询就变慢啦。
分库分表主要有水平拆分、垂直拆分的说法,拆分策略有。而分库分表主要有这些问题:
最后的话,跟大家聊来一些写 SQL 的经验吧:
参考文章:
https://mp.weixin..com/s/DpA6RTvGl-_mQbb6hVOruQ
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/743.html