
MySQL属于传统的关系型数据库产品,其开放式的架构使得用户的选择性很强,而且随着技术的逐渐成熟,MySQL支持的功能也越来越多,性能也在不断地提高,对平台的支持也在增多,此外,社区的开发与维护人数也很多。
当下,MySQL因为其功能稳定、性能卓越,且在遵守GPL协议的前提下,可以免费使用与修改,因此深受用户喜爱。
自甲骨文公司收购MySQL之后,MySQL在商业数据库与开源数据库领域的市场占有份额都跃居第一,这样的格局引起了部分业内人士的担忧,因为商业数据库的老大有可能将MySQL闭源,为了避免Oracle将MySQL闭源,而无开源的类MySQL数据库可用,MySQL社区采用了分支的方式,MariaDB数据库就这样诞生了。
MariaDB是一个向后兼容的数据库产品,可能会在以后替代MySQL,其官方地址为。不过,这里还是建议大家选择更稳定且使用更广泛的MySQL数据库,可以先测试MariaDB数据库,等使用的人员多一些,社区更活跃后再正式考虑使用也不迟。
python连接Mysql数据库,借助的第三方库是pymysql,进行下载pymysql:
pip的仓库一般都是在国外的服务器上,加了镜像源可以提供下载的速度。
常见pip镜像源(国内源)
清华:
阿里云:
中国科技大学:
华中理工大学:
山东理工大学:
豆瓣:
临时使用pip镜像源可以在使用pip的时候加参数:
Linux下,修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件。文件夹要加“.”,表示是隐藏文件夹)
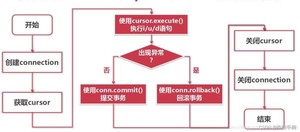
简单描述一下 Python 访问 MySQL 的步骤?
1、导入pymysql模块
2、用于模块的connect()方法创建数据库对象
3、利用数据库对象的cursor()方法创建Cursor对象
4、用Cursor对象的execute()方法执行数据库增删改查操作,查询时可用fetchone()和fetchall()查看数据
5、用数据库对象的commit()方法提交数据
6、关闭数据库对象和Cursor对象
在项目中,导入pymysql第三方库,配置连接mysql数据库:
连接成功会打印连接对象:
pymysql.connect(···)返回就是Connection类的对象,接下来,看下Connection类的源码:
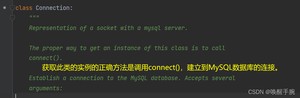
配置参数,就是Connect类生成对象需要的参数,当然这些参数一般我们会建立配置文件来进行配置,配置文件可以是,也可以是,就是把配置项从程序代码中解耦出来:
这边举例,建立文件,作为连接MySQL的配置文件:
配置文件的配置项,读取的时候默认都是以字符串类型的,对应字符串,不需要加双引号
建立完配置文件mysql_db.ini,就需要在项目中导入配置文件中的配置项:那么对于文件,在python中可以借助与configpaerser库进行读写。
configparser库相关的源码分析:
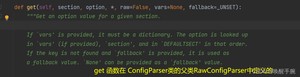
对于读取ini文件需要生成ConfigParser类的对象,ConfigParser类是继承RawConfigParser类。
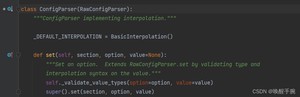
ConfigParser类的对象有read_file()函数,参数需要传入File对象,file对象可以open()函数生成,当然不仅可以传入File对象,但必须是可迭代的对象,The ‘f’ argument must be iterable.
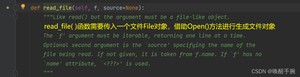
get 函数就是获取中的option配置项,section是部分,每个section部分都有若干的option配置项。
pymysql加载ini文件配置项,具体代码展示:
解释下有同学之前目录读取的问题:
python读文件需要输入的目录参数,列出以下例子:
path = r"C:User emppython.txt"
path1 = r"c:User emppython.txt"
path2 = “c:User emppython.txt”
path3 = “c:/User/temp/python.txt”
打开文件函数open()中的参数可以是path也可以是path1、path2、path3。
path:为字符串中的特殊字符,加上r后变为原始字符串,则不会对字符串中的、进行字符串转义
path1:大小写不影响windows定位到文件
path2:用一个"“取消第二个”“的特殊转义作用,即为
path3:用正斜杠做目录分隔符也可以转到对应目录,并且在python中path3的方式也省去了转义的烦恼
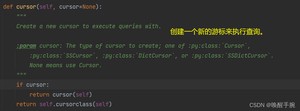
conn.cursor() : 获取游标
要想操作数据库,光连接数据是不够的,必须拿到操作数据库的游标,才能进行后续的操作,比如读取数据、添加数据。通过获取到的数据库连接实例conn下的cursor()方法来创建游标。游标用来接收返回结果。
说明:cursor返回一个游标实例对象,其中包含了很多操作数据的方法,比如执行sql语句。源码展示如下:
执行sql语句execute和executemany
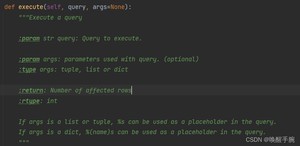
函数作用:执行单条的sql语句,执行成功后返回受影响的行数
execute 参数说明:
:要执行的sql语句,字符串类型
:可选的序列或映射,用于query的参数值。如果args为序列,query中必须使用%s做占位符;如果args为映射,query中必须使用%(key)s做占位符

函数作用:批量执行sql语句,比如批量插入数据,执行成功后返回受影响的行数
参数说明:
:要执行的sql语句,字符串类型
:嵌套的序列或映射,用于query的参数值
execute和executemany 注意:
- 数据库性能瓶颈很大一部份就在于网络IO和磁盘IO,将多个sql语句放在一起,只执行一次IO,可以有效的提升数据库性能。【推荐此方法】
- 用executemany()方法一次性批量执行sql语句,固然很好,但是当数据一次传入过多到server端,可能造成server端的buffer溢出,也可能产生一些意想不到的麻烦。所以,合理、分批次使用executemany是个合理的办法
excute执行SQL语句的时候,必须使用参数化的方式,否则必然产生SQL注入漏洞。
注意:批量插入多条sql语句采用的是executemany(sql, args)函数,返回受影响的行数。args参数是一个包含多个元组的列表,每个元组对应一条mysql中的一条数据。这里的%s不需要加引号,否则插入数据的数据会类型错误。
pymysql 查询数据
使用execute()函数得到的只是受影响的行数,并不能真正拿到查询的内容。cursor对象还提供了3种提取数据的方法:fetchone、fetchmany、fetchall.。每个方法都会导致游标动,所以必须注意游标的位置。
: 获取游标所在处的一行数据,返回元组,没有返回None
: 接受size行返回结果行。如果size大于返回的结果行的数量,则会返回cursor.arraysize条数据。
: 接收全部的返回结果行。
注意:从execute()函数的查询结果中取数据,以元组的形式返回游标所在处的一条数据,如果游标所在处没有数据,将返回空元组,该数据执行一次,游标向下移动一个位置。fetchone()函数必须跟exceute()函数结合使用,并且在exceute()函数之后使用
cursor.fetchmany(size):接受size行返回结果行。如果size大于返回的结果行的数量,则会返回cursor.arraysize条数据。
注意:从exceute()函数结果中获取游标所在处的size条数据,并以元组的形式返回,元组的每一个元素都也是一个由一行数据组成的元组,如果size大于有效的结果行数,将会返回cursor.arraysize条数据,但如果游标所在处没有数据,将返回空元组。查询几条数据,游标将会向下移动几个位置。fetmany()函数必须跟exceute()函数结合使用,并且在exceute()函数之后使用
: 接收全部的返回结果行
注意:获取游标所在处开始及以下所有的数据,并以元组的形式返回,元组的每一个元素都也是一个由一行数据组成的元组,如果游标所在处没有数据,将返回空元组。执行完这个方法后,游标将移动到数据库表的最后.
代码示例:操作cursor游标进行更新单条数据
代码示例:操作cursor游标更新多条数据
代码示例:删除单条数据
代码示例:删除多条数据
特别注意
记住在进行完增删改查之后,必须要提交事务的操作,否则操作将不生效,pymysql中提交事务的操作是:
事务操作的基本介绍
事务:一个最小的不可再分的工作单元;通常一个事务对应一个完整的业务 ( 例如银行账户转账业务,该业务就是一个最小的工作单元 )
事务四大特征(ACID):
:事务是最小单位,不可再分
:事务要求所有的DML语句操作的时候,必须保证同时成功或者同时失败
:事务A和事务B之间具有隔离性
:是事务的保证,事务终结的标志(内存的数据持久到硬盘文件中)
回滚事务的案例操作:
视图又称为虚表,是一组数据的虚拟表示,本质就是一条select语句的结果集,视图本身没有数据,它只包含映射到基类表的查询语句,所以基类表数据发生变化,视图也随之变化。
视图语法示例:
视图作用:
- 简化复杂查询,如果经常进行复杂的查询语句,可为该复杂查询语句建立视图,之后查询该视图即可
- 限制数据访问,视图本质就是一条select语句,所以访问视图时,只能访问到对应的select语句查询的列,对基类其它列的数据起到安全和保密作用
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
存储过程的特点
创建一个简单的存储过程
调用存储过程:
MySQL 存储过程的变量 (declare)
(1)、变量的声明使用declare,一句declare只声明一个变量,变量必须先声明后使用;
(2)、变量具有数据类型和长度,与mysql的SQL数据类型保持一致,因此甚至还能制定默认值、字符集和排序规则等;
(3)、变量可以通过set来赋值,也可以通过select into的方式赋值;
(4)、变量需要返回,可以使用select语句,如:select 变量名。
面对大量的web请求和插入与查询请求,mysql连接会不稳定,针对错误’Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)’
连接池的优势:在程序创建连接的时候从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度。
DBUtils是Python的一个用于实现数据库连接池的模块
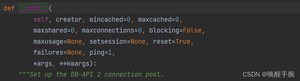
:最少的空闲连接数,如果空闲连接数小于这个数,pool会创建一个新的连接。
:最大的空闲连接数,如果空闲连接数大于这个数,pool会关闭空闲连接。
:最大的连接数,进程中最大可创建的线程数。
: 当连接数达到最大连接数时,再次请求时,如果这个值是True,请求连接的程序会一直等待,直到当前连接数小于最大连接数;如果这个值为False,会报错。
:当连接数达到这个数时,新请求的连接会分享已经分配出去的连接。
PooledDB :提供线程间可共享的数据库连接,把连接放回连接池而不是真正的关闭,可重用。
具体的代码如下所示:5 代表连接池中的初始空闲连接数量,进行打散字典
源码介绍:这是PooledDB类初始化的函数
关于取连接的connection()函数,在源码注释中都有详细的介绍,大家查看了解就行!

数据库连接连接池:服务器端的状态,可以看到有5个空闲的连接,Sleep状态。
首先我们在Linux操作系统中进行登录MySQL时候,启用命令行交互的客户端登录:
解决cursor未关闭造成的死锁
SELECT * FROM information_schema.INNODB_TRXG; 找到对应的trx_mysql_thread_id,然后执行kill id;
接口响应时间超长,耗时几十秒才返回错误提示,后台日志中出现Lock wait timeout exceeded; try restarting transaction的错误
问题场景:
1、在同一事务内先后对同一条数据进行插入和更新操作;
2、分布式服务操作同一条记录;
3、瞬时出现高并发现象;
问题原因:
1、在高并发的情况下,Spring事物造成数据库死锁,后续操作超时抛出异常。
2、Mysql数据库采用InnoDB模式,默认参数:innodb_lock_wait_timeout设置锁等待的时间是50s,一旦数据库锁超过这个时间就会报错
方案一:调整超时参数
当锁等待超时后innodb引擎报此错误,等待时间过长的语句被回滚(不是整个事务)。如果想让SQL语句等待其他事务更长时间之后完成,你可以增加参数innodb_lock_wait_timeout配置的值。
如果有太多长时间运行的有锁的事务,你可以减小这个innodb_lock_wait_timeout的值,在特别繁忙的系统,你可以减小并发。
InnoDB事务等待一个行级锁的时间最长时间(单位是秒),超过这个时间就会放弃。默认值是50秒。一个事务A试图访问一行数据,但是这行数据正在被另一个innodb事务B锁定,此时事务A就会等待事务B释放锁,等待超过innodb_lock_wait_timeout设置的值就会报错ERROR 1205 (HY000):
innodb_lock_wait_timeout是动态参数, 默认值50秒,最小值是1秒,最大值是;
set innodb_lock_wait_timeout=1500等价于set session只影响当前sessio。set global innodb_lock_wait_timeout=1500作为全局的修改方式,只会影响修改之后打开的session,不能改变当前session。
方案二:解决死锁
1、查看数据库当前的进程
show processlist会显示出当前正在执行的sql语句列表,找到消耗资源最大的那条语句对应的id.
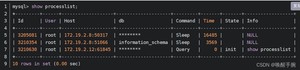
2、查看当前的锁和事务
在5.5中,information_schema 库中增加了三个关于锁的表(inndodb引擎):
当前运行的所有事务
当前出现的锁
锁等待的对应关系
看里面是否有正在锁定的事务线程,看看ID是否在show processlist里面的sleep线程中,如果是,就证明这个sleep的线程事务一直没有commit或者rollback而是卡住了。
3、查询产生锁的具体sql
根据具体的sql,就能看出是不是死锁了,并且可以确定具体是执行了什么业务,是否可以kill;
4、杀掉死锁的事务
查询出所有有锁的事务对应的线程ID(注意是线程id,不是事务id),通过information_schema.processlist表中的连接信息生成需要处理掉的MySQL连接的语句临时文件,然后执行临时文件中生成的指令。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/8371.html