
导读:极大似然估计(MLE) 是统计机器学习中最基本的概念,但是能真正全面深入地理解它的性质和背后和其他基本理论的关系不是件容易的事情。极大似然估计和以下概念都有着紧密的联系:随机变量,无偏性质(unbiasedness),一致估计(consistent),asymptotic normality,最优化(optimization),Fisher Information,MAP(最大后验估计),KL-Divergence,sufficient statistics等。在众多阐述 MLE 的文章或者课程中,总体来说都比较抽象,注重公式推导。本系列文章受3blue1brown 可视化教学的启发,坚持从第一性原理出发,通过数学原理结合模拟和动画,深入浅出地让读者理解极大似然估计。
相关链接
我们来思考这个老套问题,考虑手上有一枚硬币,旋转(抛)硬币得到正反面的概率固定(令正面概率为)但未知,我们如何能通过实验推测出

朴素的想法是,不断尝试抛硬币,随着次数 n 的增多,正面的比例会趋近于
对应到数学形式上,令我们对于 的估计为 ,则希望
假设我们尝试了n次,每次的结果为 ,为1(正面) 或 0(反面)。比如试了三次的结果是 [1, 0, 1],则 。一般,我们将观察到的数据写成向量形式
我们知道硬币的正反结果符合伯努利分布,也就是
因为 x 只有0,1两种取值,因此上式也可以写成等价如下的不含条件分支的形式
假设 ,如果做 n=10 次试验,结果应该比较接近7个1,3个0。
下面我们来模拟一下 n=10,看看结果如何。
下面代码的实现上我们直接使用了pytorch 内置的 bernoulli 函数生成 n 个随机变量实例
让我们来做三次 n=10 的试验
能发现 7个1,3个0 确实是比较可能的结果。
直觉告诉我们,当 时,根据 $P_{ber}(x;) $,7个1,3个0 出现的概率应该是最大,6个1,4个0 或者 8个1,2个0 这两种情况出现概率稍小,其他的情况概率更小。通过基本概率和伯努利公式,重复 n 次试验 1和0出现的概率可以由下面公式算出。(注:7个1,3个0不是单一事件,需要乘以组合数算出实际概率)
画出图看的很明显,1出现7次的概率确实最大。
回到我们的问题,我们先假定 的硬币做 n=10 次试验的结果就是 7个1,3个0,或者具体序列为 [1, 0, 0, 1, 0, 1, 1, 1, 1, 1]。那么我们希望按照某种方法推测的估计值 也为 0.7。
若将这个方法也记做 ,它是 的函数,即
我们如何构建这个方法呢?很显然, 中 1 的个数就可以胜任,。这个方式确实是正确的,后面的文章我们也会证明它是MLE在伯努利分布参数估计时的计算方法。
但是伯努利分布参数估计的问题中是最简单的情况,背后对应的更一般的问题是:假设我们知道某个过程或者实验生成了某种分布 P,但是不知道它的参数 ,如何能通过反复的试验来推断 ,同时,我们希望随着试验次数的增多, 能逼近 。
由于过程是有随机性,试验结果 并不能确定一定是从 生成的,因此我们需要对所有 打分。对于抛硬币试验来说,我们穷举所有在 [0, 1] 范围内的 ,定义它的打分函数 ,并且希望我们定义的 在 时得分最高。推广到一般场景,有如下性质
如此,我们将推测参数问题转换成了优化问题
一种朴素的想法是,由于 ,因此我们每次的结果应该稍微偏向 1,如果出现了 1,就记0.7分,出现了0,记0.3分,那么我们可以用10个结果的总分来定义总得分,即最大化函数
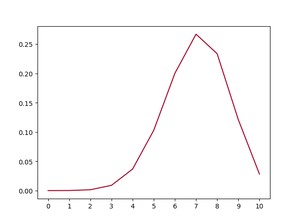
很可惜,我们定义的 f 并不符合 时取到最大的原则。下面画出了 在 [0, 1] 范围内 f 值,X 固定为 [1, 0, 0, 1, 0, 1, 1, 1, 1, 1]。显然,极值在 0.5 左右。
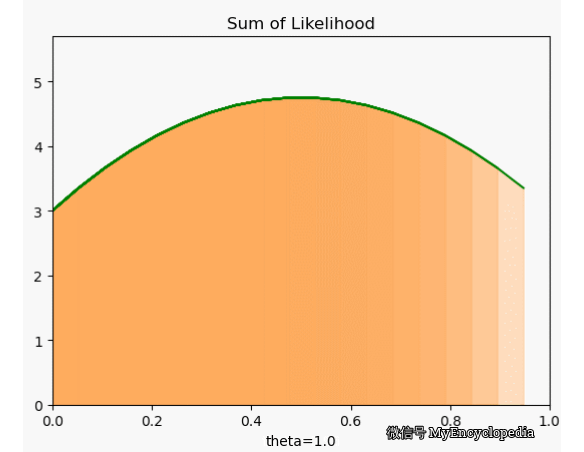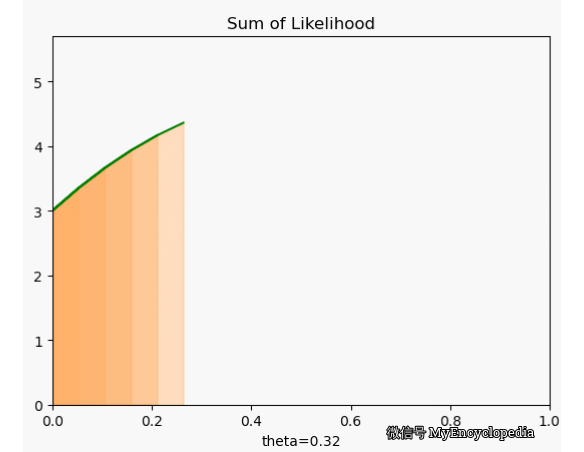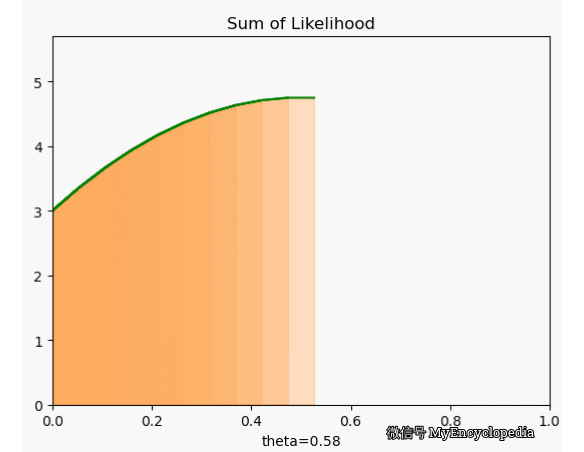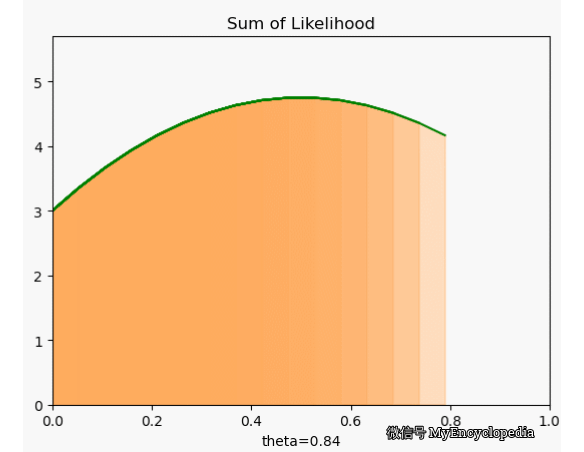
这种对于观察到的变量实例在整个参数空间打分的方法是最大似然方法的雏形。我们将每次试验结果对于不同 的打分就是似然函数的概念。
伯努利单个结果的似然函数 视为 的函数,x视为给定值,它等价于概率质量函数 PMF
有了单个结果的似然函数,我们如何定义 呢?我们定义的 需要满足,在 , 的情况下,试验最有可能的结果是 7 个1,3个0,此时 f 需要在 时取到最大值。
极大似然估计(MLE) 为我们定义了合理的 ,和朴素的想法类似,但是这次用单个结果的似然函数连乘而非连加
我们再来看一下当 $X=[1, 0, 0, 1, 0, 1, 1, 1, 1, 1] $ 时 在 空间的取值情况,果然,MLE 能在 0.7时取到最大值。
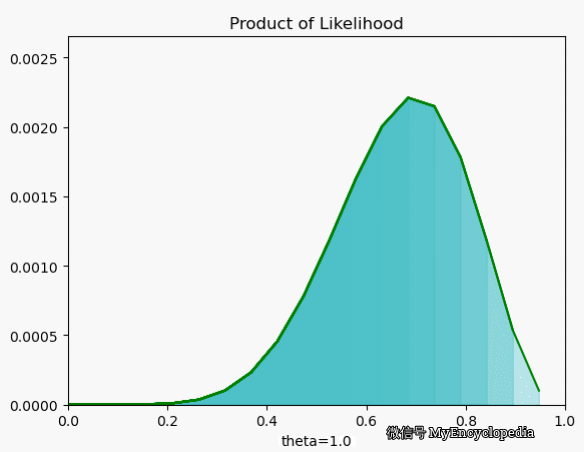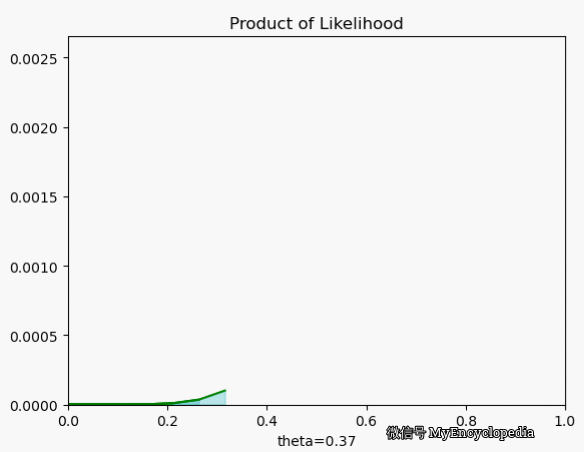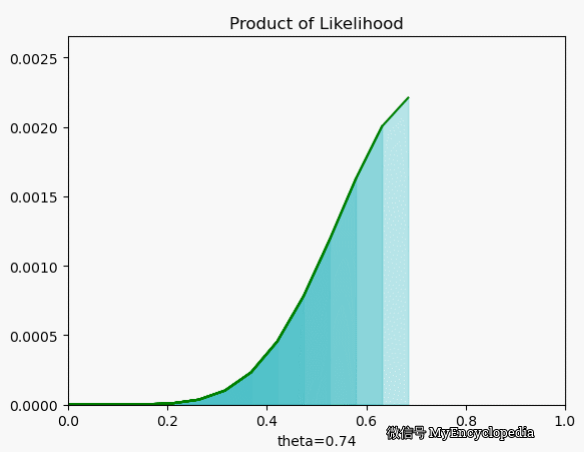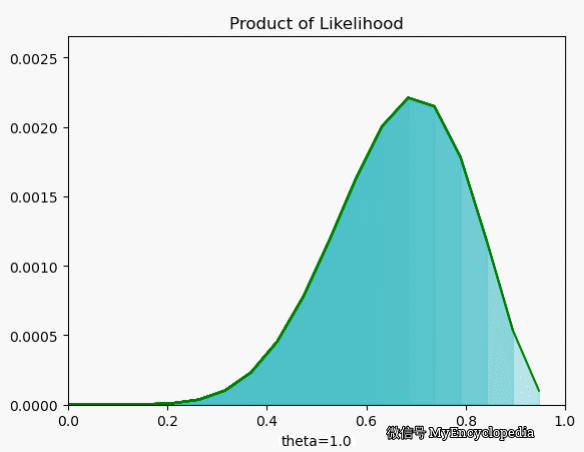
最大似然函数 $_{} L() $ 能让我们找到最可能的 ,但现实中,我们一般采用最大其 log 的形式。
理论能证明,最大对数似然函数得到的极值等价于最大似然函数。但这么做有什么额外好处呢?
我们先将对数似然函数画出来
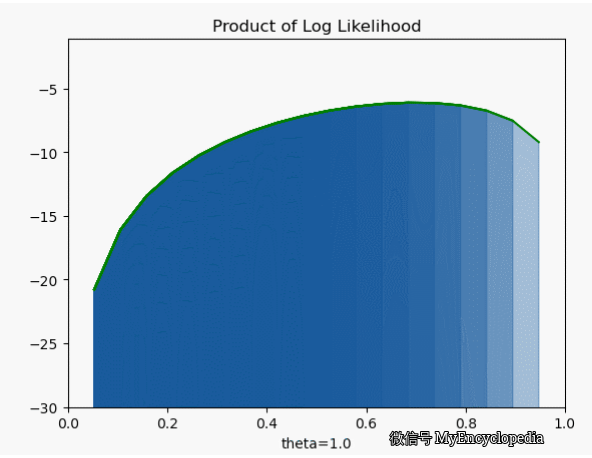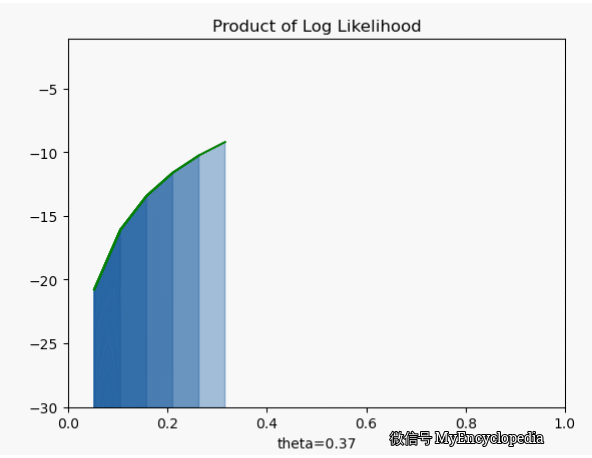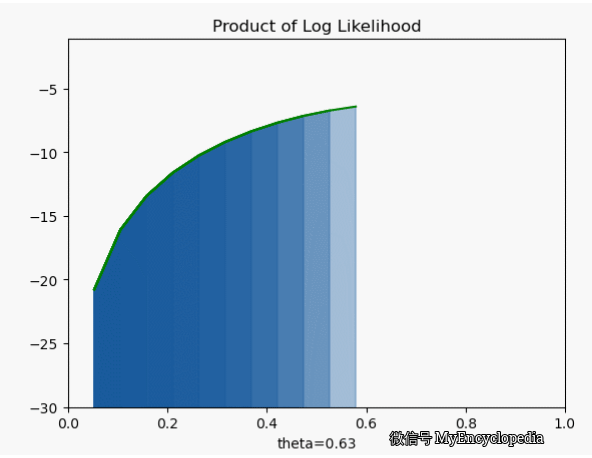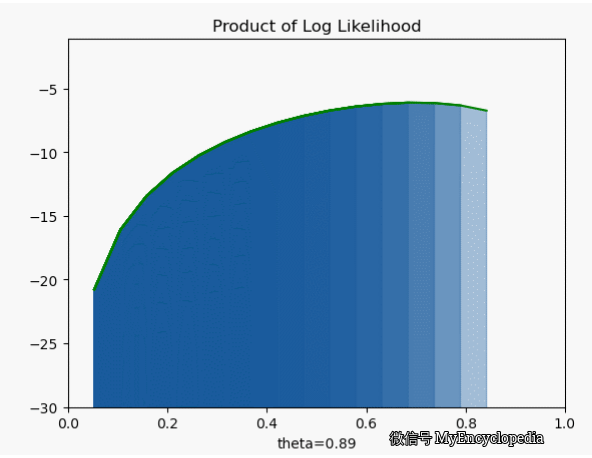
它的极大值也在 0.7,但是我们发现对数似然函数是个 concave 函数。在优化领域,最大化 concave 函数或者最小化 convex 函数可以有非常高效的解法。再仔细看之前的似然函数,它并不是一个 concave 函数。另一个非常重要的好处是,随着 n 的增大,连乘会导致浮点数 underflow,而单个点的对数似然函数的和的形式就不会有这个问题。
就让我们来实践一下,通过 pytorch 梯度上升来找到极值点。
一点需要说明的是,在迭代过程中,我们保存最后三个导数的值,当最新的三个导数都很小时就退出迭代。
运行代码,能发现最大化对数似然函数能很稳定的找到 。
现在大家对于伯努利MLE有了一定了解,接着,我们来思考一下最大化似然函数方法是否随着观察次数的增多能不断逼近真实的 呢?
的情况下,我们来这样做试验,第一次做 n=1生成观察数据 ,第二次做 n=2生成观察数据 对于每个数据集 通过最大似然方法求得估计的 将这些 画出来,可以看到,随着 ,
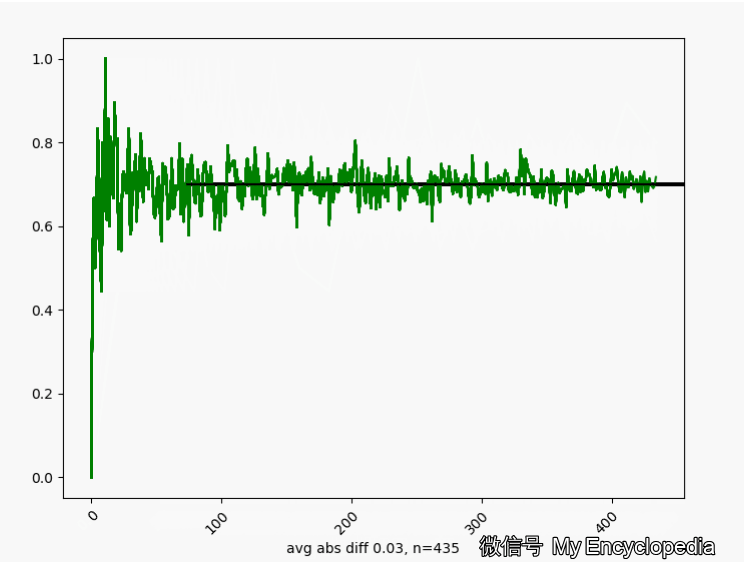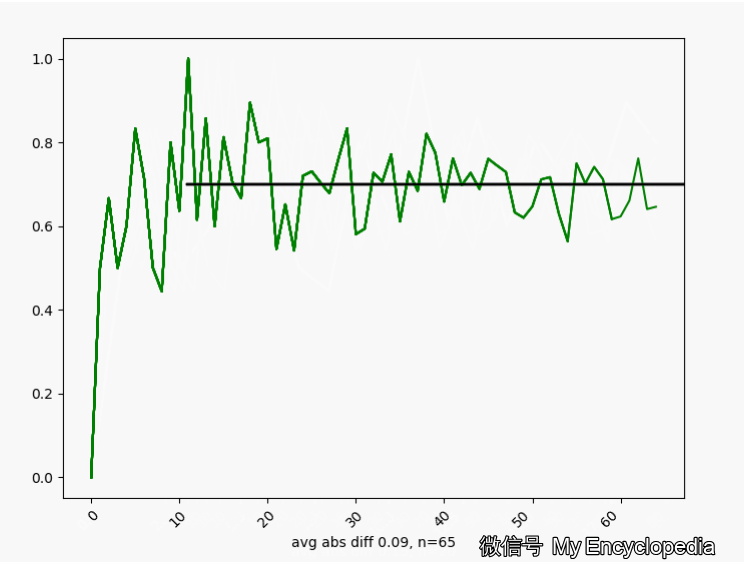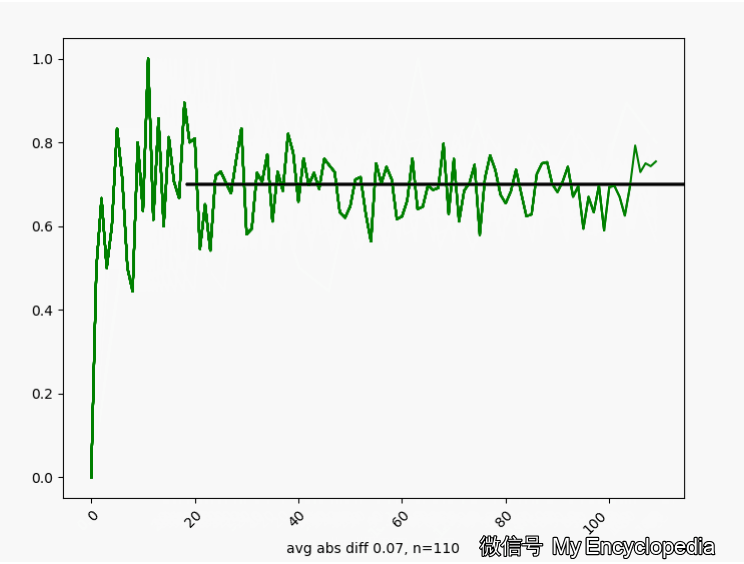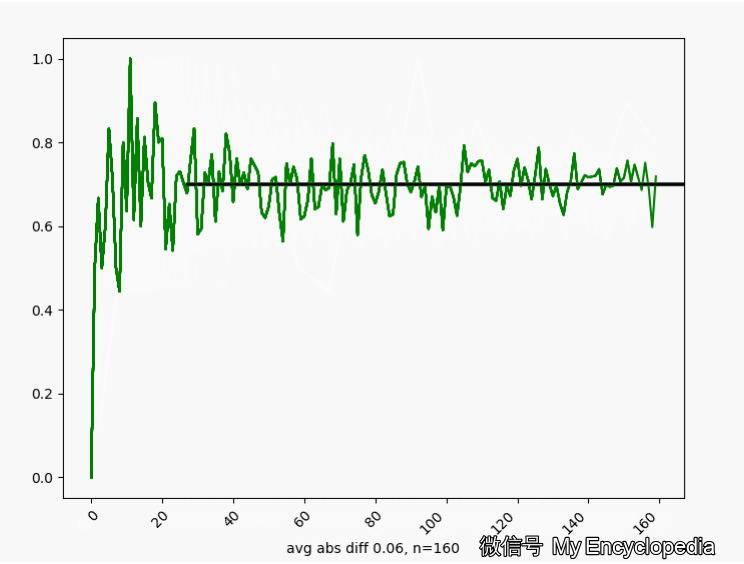
换一个角度来看一下,我们将 数列按照顺序,离散化后再归一化比例,如下图画出来,红色的柱代表了最新的值 。可以发现,初始时候, 在较远离 0.7 的地方出现,随着 n 的增大,出现的位置比较接近 0.7。
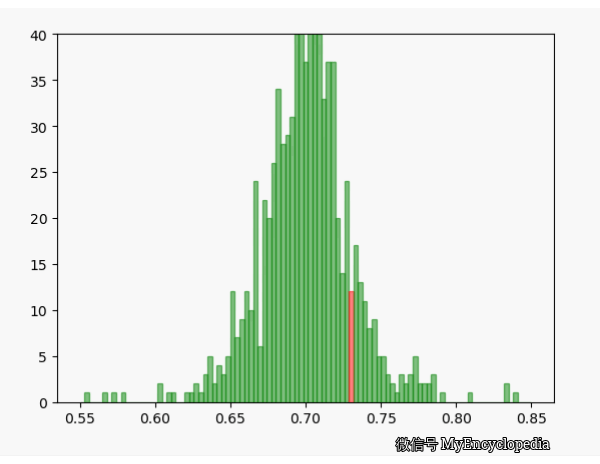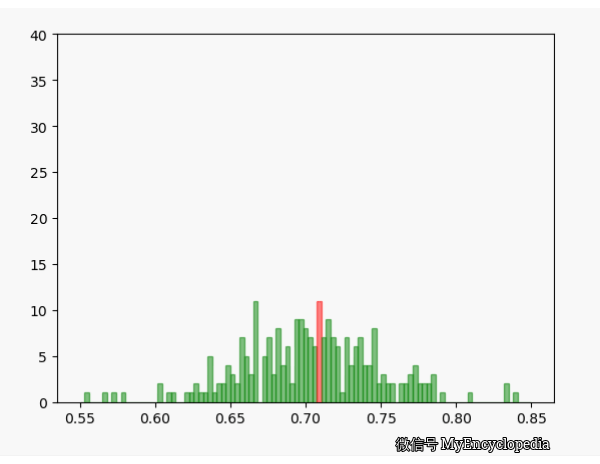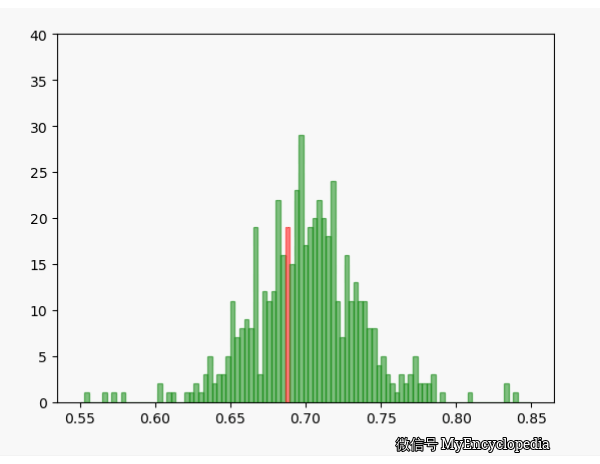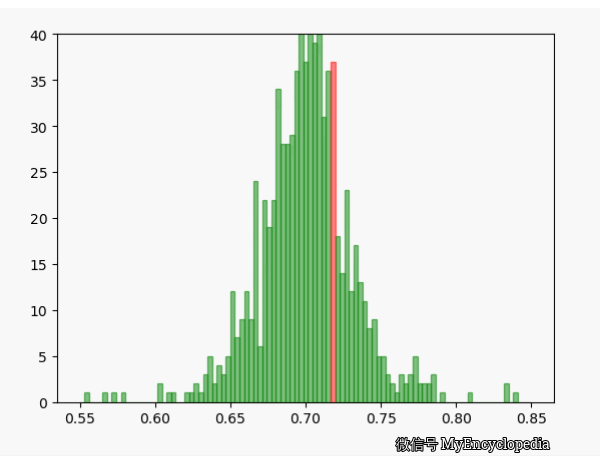
我们已经知道 MLE 方法可以通过观察数据推测出最有可能的 ,由于观察数据 是伯努利过程产生的,具有随机性,那么 可以看成是 的随机变量。我们已经通过上面的试验知道随着试验次数的增大,我们的估计会越来越逼近真实值,现在的问题是对于固定的n, 的方差是多少,它的均值是否是无偏的呢?
带着这样的疑问,我们现在做如下试验:
固定 n=10,重复做实验,画出随着次数增多 的分布,见图中绿色部分。同样的,红色是 n=80 不断试验的分布变换。
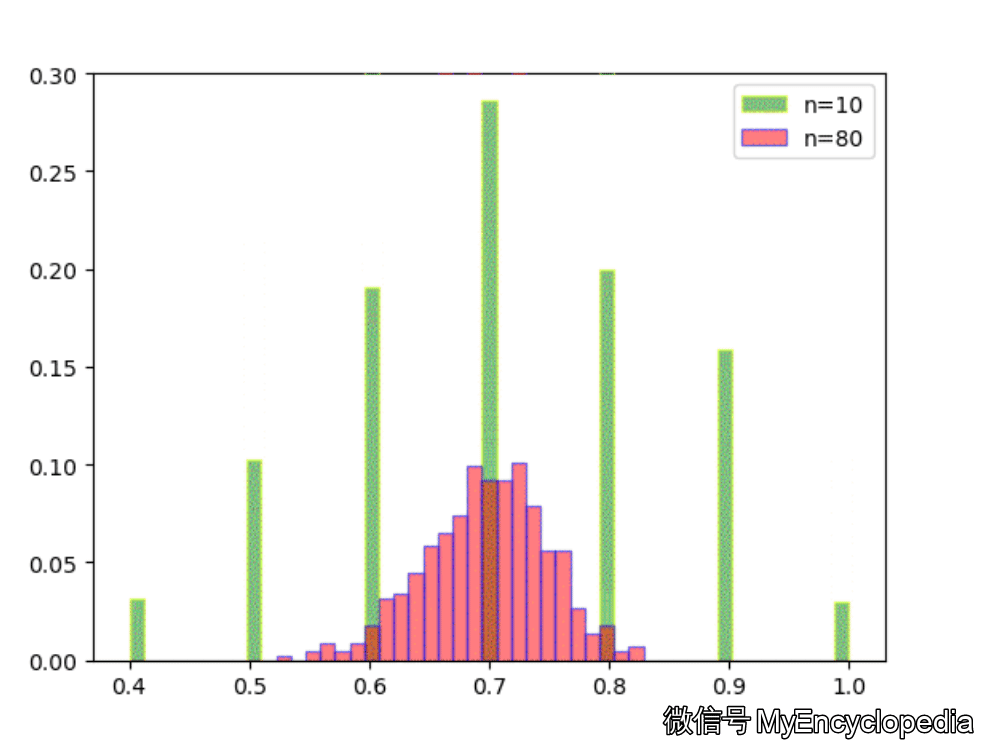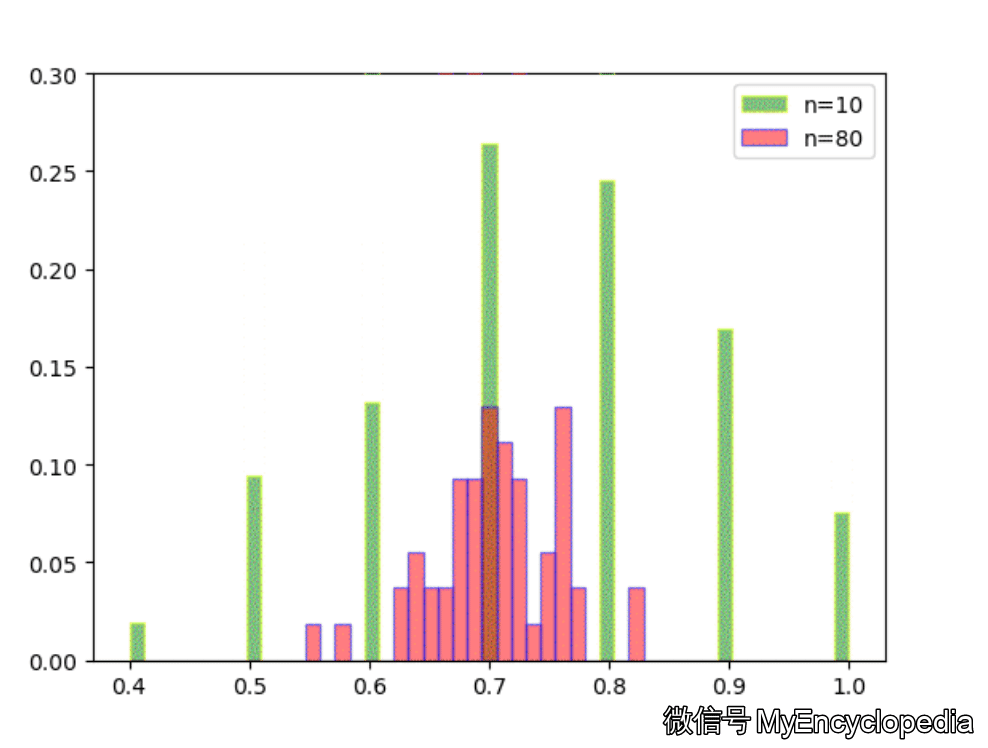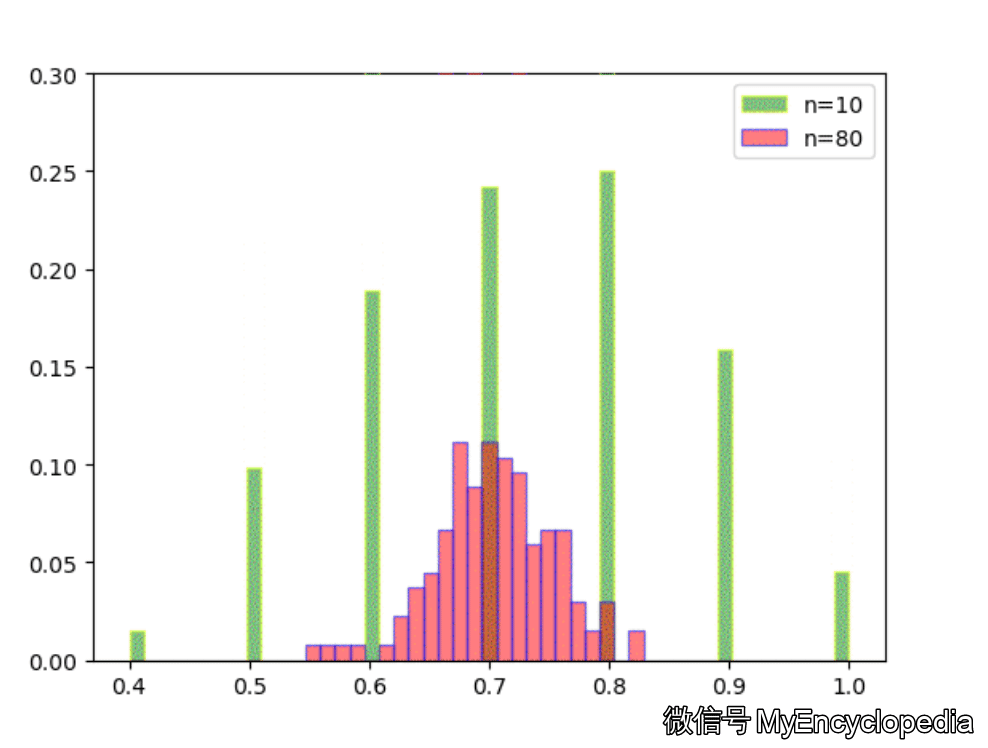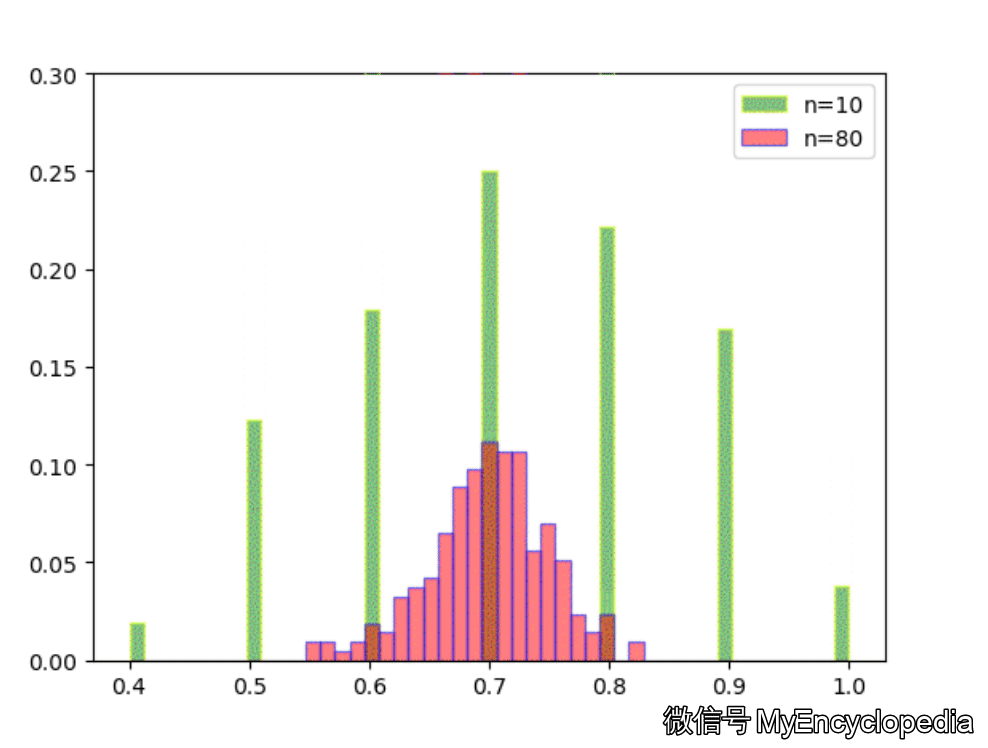
看的出来,随着试验次数的增多 - 都趋近于正态分布
- 的分散度比 $ _{80}$ 要大,即方差要大
- 的均值都在 0.7
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/8514.html