
为什么选择跳表?
目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等。跳表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
用跳表吧,跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,就能轻松实现一个 SkipList。
Redis为什么用跳表而不用平衡树?
漫画:什么是跳表?
跳表(Skiplist)是一个特殊的链表,相比一般的链表,有更高的查找效率,可比拟二叉查找树,平均期望的查找、插入、删除时间复杂度都是O(logn),许多知名的开源软件(库)中的数据结构均采用了跳表这种数据结构。
- Redis中的有序集合zset
- LevelDB、RocksDB、HBase中Memtable
- ApacheLucene中的TermDictionary、Posting List
我们先来看一下单向链表如何实现查找

假设我们有个有序链表,可知其。相比数组,链表不能进行二分查找的原因在于,不能用下标索引进行常数复杂度数据访问,从而不能每次每次快速的筛掉现有规模的一半。那么如何改造一下链表使之可以进行二分?
利用 map 构造一个下标到节点的映射?这样虽然可以进行二分查询了,但是每次插入都会引起后面所有元素的下标变动,从而需要在 map 中进行 O(n) 的更新。
增加指针使得从任何一个节点都能直接跳到其他节点?那得构造一个全连接图,指针耗费太多空间不说,每次插入指针的更新仍是 O(n) 的。
跳表给出了一种思路,跳步采样,构建索引,逐层递减。怎么提高查询效率呢?如果我们给该单链表加一级索引,将会改善查询效率。
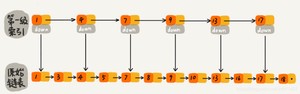
如图所示,当我们每隔一个节点就提取出来一个元素到上一层,把这一层称作索引,其中的down指针指向原始链表。
当我们查找元素16的时候,单链表需要比较10次,而加过索引的两级链表只需要比较7次。当数据量增大到一定程度的时候,效率将会有显著的提升。
如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
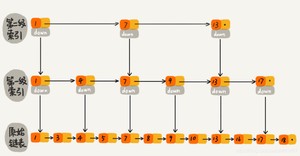
这基本上就是跳表的核心思想,其实是一种通过的一个算法,通过在每个节点中增加了向前的指针(即层),从而提升查找的效率。
- 跳跃列表是按层建造的。
- 底层是一个普通的有序链表。每个更高层都充当下面列表的「快速跑道」,这里在层 i 中的元素按某个固定的概率 p
(通常为0.5或0.25)出现在层 i+1 中。 - 平均起来,每个元素都在 1/(1-p) 个列表中出现, 而最高层的元素(通常是在跳跃列表前端的一个特殊的头元素),在 O(log1/p n) 个列表中出现。
2.1、SkipList基本数据结构及其实现
一个跳表,应该具有以下特征:
- 1,一个跳表应该有几个层(level)组成;
- 2,跳表的第一层包含所有的元素;
- 3,每一层都是一个有序的链表;
- 4,如果元素x出现在第i层,则所有比i小的层都包含x;
- 5,每个节点包含key及其对应的value和一个指向同一层链表的下个节点的指针数组
跳表可视为、的位置(Position,对Entry的访问抽象)的二维集合,,跳表的各个位置可以通过如下方式进行遍历。
- :返回和P在同一Level的后面的一个位置,若不存在则返回NULL。
- :返回和P在同一Level的前面的一个位置,若不存在则返回NULL。
- :返回和P在同一Tower的下面的一个位置,若不存在则返回NULL。
- :返回和P在同一Tower的上面的一个位置,若不存在则返回NULL。
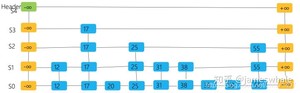
有顺序关系的多个集合M可以由跳表实现,跳表S由一系列组成, - 其中h代表跳表的高度
- 每个列表Si按Key顺序存储M项的子集,并额外增加两个特殊键,分别是,其中,。
此外,S中的列表满足以下要求(不同实现版本要求会有不同)。
- 列表S0包含集合M的每个Entry(加上带有的特殊Entry)。
- 对于,列表包含(包括)列表中Entry的随机生成子集。
- 列表Sh只包含。
Si中的Entry是从Si-1中的Entry集合中随机选择的,,以来决定是否需要拷贝到Si中,我们期望。
。从一个列表到下一个列表的Entry数减半并不是跳表的强制性要求,相反借助来达成。
跳表基本数据结构
定义跳表数据类型:
其中level是当前跳表最大层数,head是指向跳表的头节。
跳表的每个节点的数据结构:

上面的每个结构体对应着图中的每个节点,如果一个节点是一层的节点的话(如7,12等节点),那么对应的next将指向一个只含一个元素的数组,以此类推。
对于这个结构体重点说说, 其实它是个柔性数组,主要用于使结构体包含可变长字段。我们可以通过如下方法得到包含可变
层数(n)的Node *类型的内存空间:
通过上面我们可以根据层数n来申请指定大小的内存,从而节省了不必要的内存空间(比如固定大小的next数组就会浪费大量的内存空间)。
4.1、跳表的创建
跳表的创建
列表的初始化需要初始化头部,并使头部每层(根据事先定义的MAX_LEVEL)指向末尾(NULL)
4.2、跳表查找操作
- 1、从最上层的链(Sh)的开头开始
- 2、假设当前位置为p,它向右指向的节点为q(p与q不一定相邻),且q的值为y。将y与x作比较
- 3、如果当前位置在最底层的链中(S0),且还要往下移动的话,则输出查询失败
4.3、跳表插入操作
1、目的:向跳跃表中插入一个元素x
2、首先明确,向跳跃表中插入一个元素,相当于在表中插入一列从S0中某一位置出发向上的连续一段元素。有两个参数需要确定,即插入列的位置以及它的“高度”。
3、 关于插入的位置,我们先利用跳跃表的查找功能,找到比x小的最大的数y。根据跳跃表中所有链均是递增序列的原则,x必然就插在y的后面。
4、跳表是一种随机化数据结构,其随机化体现在插入元素的时候元素所占有的层数完全是随机的。而插入列的“高度”较前者来说显得更加重要。为了使插入数据之后,保持该数据结构进行各种操作均为O(logn)复杂度的性质,我们引入随机化算法(Randomized Algorithms)。
- 相当与做一次丢硬币的实验,如果遇到正面(rand产生奇数),继续丢,遇到反面,则停止,用实验中丢硬币的次数level作为元素占有的层数。
- 显然随机变量 level 满足参数为 ,
就是说,各个元素的层数,期望值是 2 层。
随机决策过程:
- 1、产生一个0到1的随机数r ,
- 2、如果r小于一个常数p,则执行方案A, ,否则,执行方案B
- 3、初始时列高为1。插入元素时,不停地执行随机决策模块。如果要求执行的是A操作,则将列的高度加1,并且继续反复执行随机决策模块。直到第i次,模块要求执行的是B操作,我们结束决策,并向跳跃表中插入一个高度为i的列。
由于跳表数据结构整体上是有序的,所以在插入时,需要首先查找到合适的位置,然后就是修改指针(和链表中操作类似),然后更新跳表的level变量。 跳表的插入总结起来需要三步:
- 1:查找到待插入位置, 每层跟新update数组;
- 2:需要随机产生一个层数;
- 3:从高层至下插入,与普通链表的插入完全相同;
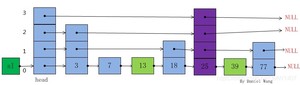
比如插入key为25的节点,如下图
- 对于步骤1,我们需要对于每一层进行遍历并保存这一层中下降的节点(其后继节点为NULL或者后继节点的key大于等于要插入的key),如下图,节点中有白色星花标识的节点保存到update数组。
- 对于步骤2我们上面已经说明了是通过一个随机算法产生一个随机的层数,但是当这个随机产生的层数level大于当前跳表的最大层数时,我们此时需要更新当前跳表最大层数到level之间的update内容,这时应该更新其内容为跳表的头节点head。然后就是更新跳表的最大层数。
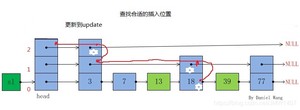
- 对于步骤3就和普通链表插入一样了,只不过现在是对每一层链表进行插入节点操作。最终的插入结果如图所示,因为新插入key为25的节点level随机数值为4,大于插入前的最大层数,所以此时跳表的层数为4。
实现代码如下:
4.4、跳表 删除操作
删除节点操作和插入差不多,找到每层需要删除的位置,删除时和操作普通链表完全一样。不过需要注意的是,如果该节点的level是最大的,则需要更新跳表的level。
删除操作分为以下三个步骤:
- 在跳跃表中查找到这个元素的位置,如果未找到,则退出
- 将该元素所在整列从表中删除
- 将多余的“空链”删除
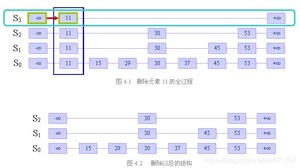
删除节点操作和插入差不多,找到每层需要删除的位置,删除时和操作普通链表完全一样。不过需要注意的是,如果该节点的level是最大的,则需要更新跳表的level。
4.5、跳表的销毁
上面分别介绍了跳表的创建、节点插入、节点删除,其中涉及了内存的动态分配,在使用完跳表后别忘了释放所申请的内存,不然会内存泄露的。
4.6、完整代码
skiplist.h
skiplist.cpp

test.cpp
1、https://blog.csdn.net/daniel_ustc/article/details/
2、https://www.zhihu.com/search?type=content&q=%E8%B7%B3%E8%A1%A8
3、https://zhuanlan.zhihu.com/p/
4、http://www.cppblog.com/mysileng/archive/2013/04/06/199159.html
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/887.html