
什么是表分区?表分区其实就是将一张大数据量表中的数据按照不同的分区策略分配到不同的系统分区、硬盘或是不同的服务器设备上,实现数据的均衡分配,这样做的好处是均衡大数据量数据到不同的存储介子中,这样每个分区均摊了一部分数据,然后可以定位到指定的分区中,对数据表进行需求操作,另外,也方便管理水表,比如要删除某个时间段的数据,就可以按照日期分区,然后直接删除该日期分区即可,并且效率相对于传统的DELETE数据效率高很多,这里以Mysql为例进行说明。
· 分区分表区别
· 表分区的原理
· 表分区的策略
· 表分区的实施
· 表分区的注意
一、分区分表区别
分区和分表针对的都是数据表,而分表是真正的生成数据表,是将一张大数据量的表分成多个小表实现数据均衡;分区并不是生成新的数据表,而是将表的数据均衡分摊到不同的硬盘,系统或是不同服务器存储介子中,实际上还是一张表。另外,分区和分表都可以做到将表的数据均衡到不同的地方,提高数据检索的效率,降低数据库的频繁IO压力值,分区的优点如下:
1、相对于单个文件系统或是硬盘,分区可以存储更多的数据;
2、数据管理比较方便,比如要清理或废弃某年的数据,就可以直接删除该日期的分区数据即可;
3、精准定位分区查询数据,不需要全表扫描查询,大大提高数据检索效率;
4、可跨多个分区磁盘查询,来提高查询的吞吐量;
5、在涉及聚合函数查询时,可以很容易进行数据的合并;
二、表分区的原理
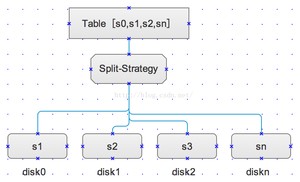
表的分区的原理理解起来比较简单,其实就是把一张大数据量的表,根据分区策略进行分区,分区设置完成之后,由数据库自身的储存引擎来实现分发数据到指定的分区中去,正如上图所示,一张数据表被分成了n个分区,并且分区被放入到不同的介子disk中,每个disk中包含自少一个分区,这就实现了数据的均衡以及通过跨分区介子检索提高了整体的数据操作IO吞吐率。
注:想通过表分区来提供查询性能,就是要提高磁盘IO性能,必然就需要实现IO的并发,所以表分区就需要放到不同的磁盘上才行。在单磁盘上进行表分区基本属于扯淡
三、表分区的策略
目前在MySql中支持四种表分区的方式,分别为HASH、RANGE、LIST及KEY,当然在其它的类型数据库中,分区的实现方式略有不同,但是分区的思想原理是相同,具体如下:
1、HASH
HASH分区主要用来确保数据在预先确定数目的分区中平均分布,而在RANGE和LIST分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中,而在HASH分区中,MySQL自动完成这些工作,你所要做的只是基于将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。
比如:
CREATE TABLE t_product_item (
id int(7) not null,
title varchar(40) not null,
subtitle varchar(60) null,
price double not null,
imgurl varchar(70) not null,
producttype int(2) not null,
createtime datetime not null
)
ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY HASH(YEAR(createtime))
PARTITIONS 10
;
上面的例子,使用HASH函数对createtime日期进行HASH运算,并根据这个日期来分区数据,这里共分为10个分区。
NOTE:
可以通过在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回整数的表达式。它可以是字段类型为MySQL 整型的一列的名字,也可以是返回非负数的表达式。另外,可能需要在后面再添加一个“PARTITIONSnum”子句,其中num 是一个非负的整数,它表示表将要被分割成分区的数量。
2、RANGE
基于属于一个给定连续区间的列值,把多行分配给同一个分区,这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。
比如:
CREATE TABLE t_product_item (
id int(7) not null,
title varchar(40) not null,
subtitle varchar(60) null,
price double not null,
imgurl varchar(70) not null,
producttype int(2) not null,
createtime datetime not null
)
ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE(producttype) (
PARTITIONP0 VALUES LESS THAN(2),
PARTITIONP1 VALUES LESS THAN(4),
PARTITIONp2 VALUES LESS THAN(6),
PARTITIONp3 VALUES LESS THAN MAXVALUE
);
上面的例子,使用了范围RANGE函数对产品类型进行分区,共分为4个分区,产品类别为0,1的对应在分区P0中,2,3类别在分区P1中,依次类推即可。那么类别编号大于6的怎么分区呢?我们可以使用MAXVALUE来将大于6的数据统一存放在分区P3中即可。
3、LIST
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择分区的。LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr” 是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。
比如:
DROP TABLE IF EXISTS t_product_item;
CREATE TABLE t_product_item (
id int(7) not null,
title varchar(40) not null,
subtitle varchar(60) null,
price double not null,
imgurl varchar(70) not null,
producttype int(2) not null,
createtime datetime not null
)
ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY LIST(producttype) (
PARTITIONP0 VALUES IN (0,1),
PARTITIONP1 VALUES IN (2,3),
PARTITIONP2 VALUES IN (4,5),
PARTITIONP3 VALUES IN (6,7,8,9,10,11,12)
)
上面的例子,使用了列表匹配LIST函数对产品类型进行分区,共分为4个分区,产品类别为0,1的对应在分区P0中,2,3类别在分区P1中,依次类推即可。那么类别编号大于12的怎么分区呢?这里不同于RANGE,LIST分区的数据必须匹配列表中的产品类别才能进行分区。
4、KEY
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
比如:
CREATE TABLE t_product_item (
id int(7) not null,
title varchar(40) not null,
subtitle varchar(60) null,
price double not null,
imgurl varchar(70) not null,
producttype int(2) not null,
createtime datetime not null
)
ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY KEY(producttype)
PARTITIONS 10;
NOTE:
此种分区算法目前使用的比较少,大家知道其存在和怎么使用即可。
四、表分区的实施
这里我以HASH分区算法为例,进行数据表分区的实现,具体如下:
1、建分区表
sql:
DROP TABLE IF EXISTS t_product_item;
CREATE TABLE t_product_item (
id int(7) not null,
title varchar(40) not null,
subtitle varchar(60) null,
price double not null,
imgurl varchar(70) not null,
producttype int(2) not null,
createtime datetime not null
DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP
)
ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE(producttype) (
PARTITIONP0 VALUES LESS THAN(2),
PARTITIONP1 VALUES LESS THAN(4),
PARTITIONp2 VALUES LESS THAN(6),
PARTITIONp3 VALUES LESS THAN MAXVALUE
)
NOTE:
这里使用了range算法分区,目前分为4个分区,分区是按照产品的类别进行划分,具体说明请查看上面的range讲解说明。
2、插入数据
A、插入产品类型为0,1 共1条
insert into t_product_item(id,title,subtitle,price,imgurl,producttype)
values(0,'A','A-title',99.99,'http://null',0);
B、插入产品类型为2,3 共1条
insert into t_product_item(id,title,subtitle,price,imgurl,producttype)
values(1,'A','A-title',99.99,'http://null',3);
C、插入产品类型为4,5 共1条
insert into t_product_item(id,title,subtitle,price,imgurl,producttype)
values(2,'A','A-title',99.99,'http://null',5);
D、插入产品类型为6,7 共2条
insert into t_product_item(id,title,subtitle,price,imgurl,producttype)
values(3,'A','A-title',99.99,'http://null',6);
insert into t_product_item(id,title,subtitle,price,imgurl,producttype)
values(4,'A','A-title',99.99,'http://null',7);
insert into t_product_item(id,title,subtitle,price,imgurl,producttype)
values(5,'A','A-title',99.99,'http://null',8);
3、验证分区
首先,查看下各个分区信息及数据是否正确:
select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
andtable_name='t_product_item';
执行结果:
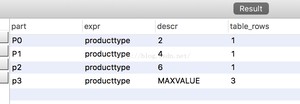
从上图知道,我们根据RNAGE算法,通过产品类型producttype进行RNAGE运算,结果插入数据的结果都已经正确的插入到对应的分区位置。
其次,使用EXPLAIN分析查询sql:
explain select * from t_product_item where producttype=3;
执行结果:

从上图知道,这次的查询数据是从partions=P0中直接查询的,而不是全表查询,所以如果数据量很大时会明显提高检索效率。
五、表分区的注意
1、引擎的统一
在对同一个表进行分区时,必须保证数据表的引擎相同,比如:不能对一个分区的表为InnoDB,而另一个分区的引擎为MySIAM。
2、分区关联性
在对数据表分区时,不能只对数据进行分区,需要连同其对应的索引等属性一同分区动作,某种程度上可以保持数据属性的完整。
3、分区的级别
对表进行分区之后,如果某个分区中的数据量依然很大或是增长迅速,那么你同样可以再进行子分区操作,将该数据再分区到其它分区中。另外,如果在一个分区中使用了子分区,那么其它的子分区也必须定义。
4、LIST分区
LIST分区没有类似如“VALUESLESS THAN MAXVALUE”这样的包含其他值在内的定义。将要匹配的任何值都必须在值列表中找到。
5、Linear线性
分区策略KEY和HASH都支持使用线性LINEAR的算法,也就是分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/961.html